Adaptive process and memory management for Python web servers
At Instagram, process and memory management is a frequent point of consideration in building large-scale, distributed, fault-tolerant systems. This need is augmented by many of our long-running applications, responsible for servicing and handling the requests of hundreds of millions of users.
Since a large part of our stack is built on Python, one common approach to this problem is the pre-fork worker process model, where worker processes are forked before a request comes in. However, while this approach simplifies the development and deployment experience, it is not without challenges. For example:
- How should we best balance number of worker processes and memory utilization for optimal server throughput?
- How should we reduce redundant work among worker processes?
- Since in most cases server processes occupy the majority of host memory, how can we ensure that it is within a healthy range?
We’ve done work on optimizing the process and memory management of our uWSGI pre-fork servers, and we’re excited to share some of our learnings.
Respawning in the uWSGI process model
uWSGI has a relatively simple but effective process model:
Step 1: At start time, the uWSGI master reads in a static config
Step 2: The uWSGI master forks a certain number of worker processes
Step 3: Each worker process handles one request at a time

Note that there are warmup costs associated with this model as well as early computations which every worker process needs to perform. Subsequently, having every worker process do this individually would be redundant and increase overall memory usage. To mitigate this, we leveraged shared memory between master and worker processes.
Nonetheless, over time — due to memory leaks, cache, memory fragmentation, etc… — the memory consumption of the worker processes kept increasing. This posed a problem as an increase in memory consumption meant decreased system reliability and efficiency (e.g. more prone to out-of-memory errors or more swapping events). In response, we periodically respawned worker processes to reclaim memory and to ensure optimal and healthy memory utilization.
Previously we used two per-worker thresholds to control respawn: reload-on-rss and evil-reload-on-rss.
- Initially, the master process allocates a piece of shared memory which contains an entry for each worker.
- A worker process starts a background thread to collect its RSS usage and updates its entry in shared memory.
- At the end of each request, a worker process checks whether its RSS is higher than
reload-on-rss. If yes, the worker process performs some cleanup tasks, sets a deadline for itself and callsexit(). - The master process checks the status of the workers against the following conditions:
- If a worker initiated the exit process but didn’t finish before the deadline, the master process will sigkill it to avoid bigger issues.
- If the RSS of a worker exceeds
evil-reload-on-rss, master process will sigkill it too.
As part of the operation, the master process also detects dead workers and will try to respawn new ones. However, since worker respawn is expensive (i.e. there are warm-up costs, LRU cache repopulation, etc..), an additional goal is to reduce respawn rate as much as possible. Previously, this was primarily achieved by increasing available memory and adjusting worker respawn thresholds (and thus their frequency).
Problems
- Legacy uWSGI respawn is based on worker RSS, which includes both shared and private memory. As mentioned earlier, the worker processes share a lot of pages with the master process. High RSS doesn’t mean reclaimable memory is also high. If the host has plenty of free memory, some worker respawns could be unnecessary.
- uWSGI processes consume most of the host physical memory. For large applications like Instagram, resource usage varies widely across different hosts (due to varying cluster workload, traffic fluctuations, etc..) Therefore, the N-per-worker-thresholds-based respawn is an unsuitable control for host level memory usage.
- uWSGI uses a static config to decide the number of worker processes. However, most of the time the number of required workers is considerably lower than the maximum number of allowed workers. As a result, ~20% to 40% of the workers remain idle for ~90% of the time. Not only is this wasted memory, but it also causes higher process contention, and TLB and cache pollution.
Solutions
As part of addressing the problems outlined above, our guiding principles were (a) reduce uWSGI respawn rate, (b) prevent resource waste, and (c) have a tight control on host memory usage to ensure the health of the system. As a result, we made the following changes to uWSGI:
1. Host memory-based respawn
We implemented host level memory utilization-based uWSGI respawn. There are still two thresholds, but they are based on host level memory utilization. For illustrative purposes, let’s call them L (for Lower bound) and U (for Upper bound).
Each worker process still runs a background thread to update its memory usage in shared memory. Master loop checks current host level memory utilization. If it’s greater than L, then the master process picks a certain number of workers with the highest memory usage and sets a flag in their corresponding entries in shared memory. At the end of each request, a worker checks this flag instead and acts accordingly. If host memory utilization is greater than U then master would sigkill the workers immediately.
The number of workers to kill is decided by a simple quadratic algorithm. The closer it is to the upper limit, the more workers we’d like to kill to avoid OOM.
2. Adaptive respawn
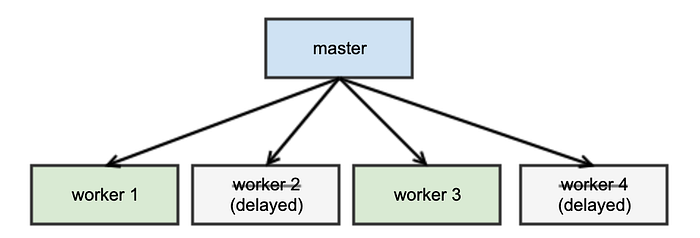
The uWSGI master monitors the size of the tcp connection backlog. The expectation is that workers are able to quickly process requests, and that the queue is short. When process parallelism is more than needed, however, we may empty the listen queue while there could be some workers still sitting idle and consuming physical memory.
To make this logic smarter, we implemented listen queue-based adaptive uWSGI respawn. Specifically, if there are at least certain number of idle workers, and if the listen queue is nearly empty, the master process will delay worker respawn. Otherwise, it’ll spawn additional worker processes (up to some limit).
Results
Both changes have proven to be successful. They have improved efficiency through better memory utilization, avoiding unnecessary worker respawns, and reduced costs related to unnecessary worker processes. As a result, we were able to achieve more than 11% capacity improvement.
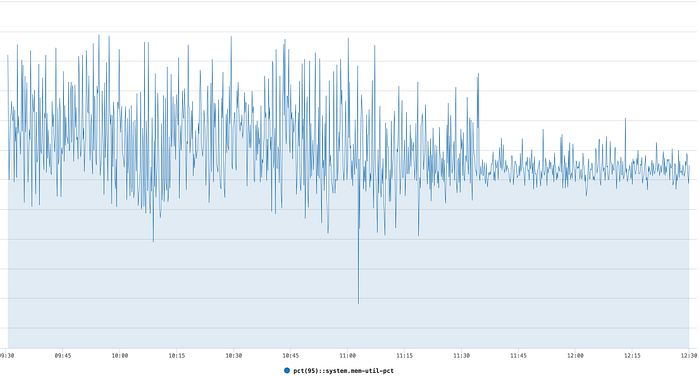
The changes also removed some spikiness in host memory utilization. It has been in much better shape now and has helped improve site reliability.
Thanks to Jianlong Zhong, Lisa Guo, Matt Page, Carl Meyer, Raymond Ng for their insights and contributions to these changes.
Qi Zhou is a software engineer at Instagram.

