This will allow us to post more regularly about the novel engineering work being done at Instagram.
To stay connected for future content, you can follow our socials here:
The Instagram Engineering Blog has a new location was originally published in Instagram Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]>Recommended content, which is surfaced in places like Explore or hashtags, is a central part of people’s experience on Instagram. As people browse this “unconnected content” from accounts that they aren’t already linked to on Instagram, it’s extremely important to identify and deal with content that violates our Community Guidelines or might be considered offensive or inappropriate by the viewer. Last year, we formed a team dedicated to finding and taking action on both violating and potentially offensive content on these unconnected surfaces of Instagram, as part of our ongoing effort to help keep our community safe.
This work differs from conventional platform work. Platform teams at Facebook traditionally focus on solving a problem across a number of surfaces, such as News Feed and Stories. However, Explore and Hashtags are particularly complicated ecosystems. We chose to create a bespoke solution that builds on the work of our platform teams, and apply it to these complex surfaces.
Now, a year later, we are sharing the lessons we learned from this effort. These changes are essential in our ongoing commitment to keep people safe on Instagram, and we hope they can also help shape the strategies of other teams thinking about how to improve the quality of content across their products.
Learning 1: Measuring quality is difficult. Operationalizing your measurement on experimentation is critical for your team’s success.
One of the toughest challenges this year has been identifying how to accurately measure the quality of content. There’s no industry benchmark when it comes to measuring quality in a deterministic way.
In addition, when measuring the quality of experiments and A/B tests from multiple engineering teams, trying to hand-label each test group subset from our experiments proved to be time intensive and unlikely to produce statistically significant results. Overall, this was not a scalable solution.
We transitioned across many different types of metrics: from using deterministic user signals to rating both test and control groups for all experiments. This transition of metrics over experimentation took significant effort and led us to spend many iteration cycles understanding the results of our experiments.

In the end, we decided to combine manual labels for calibration and software-generated scores together, to get the best of both worlds. By relying on both human labels for calibration and a classifier, we were able to scale the calibrated classifier score (in other words, the probability of a content violation at a given score) to the entire experiment. This allowed us to achieve more statistically significant approximation of impact when compared to either human labels and classifiers alone.
Conclusion: Don’t try to solve quality without operationalizing your metrics, and make sure your engineers have a reliable online metric they can reference in their experiments. Also, when thinking about quality, think about how you can rely on classifier scores and manually-labelled data to approximate the directionality and magnitude of your launches.
Learning 2: Read-path quality models can be more precise and reliable when thinking about enforcement at the ranking level.
Historically, we have always used classifiers that would predict whether a piece of content is good or bad at upload time, which we call “write-path classifiers.” Having a write-path classifier has the advantage of being efficient, but it has a major drawback: it can only look at the content itself (i.e. pixels and captions). It cannot incorporate real-time features, those which can provide a lot of insight into whether a piece of media is good or bad, such as comments or other engagement signals.
Last year, we started working on a “read-path model”. This “read path model” is an impression-level real-time classifier for detecting unwanted content (photos, videos), combining both the upload time signals and the real-time engagement signals at media and author level. This particular model, therefore, would run every time a user makes a request to see a page on Explore, scoring each candidate in real time at the request level.
This model turned out to be extremely successful. By using real time engagement signals in combination with the content features, it was capable of capturing and understanding bad behaviors associated with violating content.
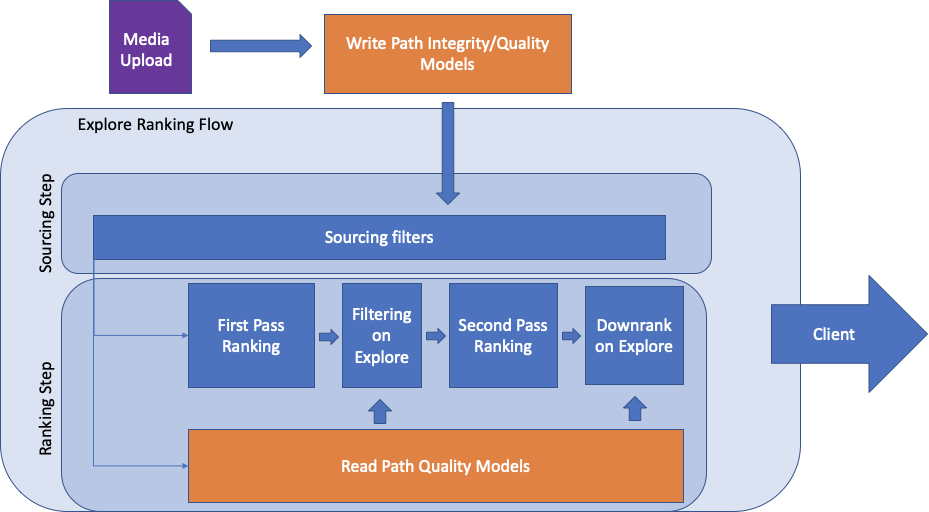
Conclusion: if you are considering applying quality signals into your ranking model, using a read-path model trained with both content-level and engagement-level features can be a more reliable and precise means of achieving better results.
Learning 3: Although read-path models are important, you must also have sourcing-level filters.
While we know read-path models are important in filtering violating and potentially inappropriate content from unconnected surfaces at ranking level, we found that having a basic level of protection at the sourcing level is still necessary. That’s where write-path level classifiers come into play.
But what does ranking and sourcing level mean? At Instagram, we have two steps to serve content to our community in Explore and hashtag pages:
- The sourcing step constitutes the queries necessary to find eligible content to show someone, with context on that person’s interests.
- The ranking step takes eligible content and ranks it according to a given algorithm/model.
We learned the following when it came to finding eligible content at the sourcing level:
- You need filters at sourcing level for low prevalence issues. Low prevalence violations are a very small volume of your training data, meaning content may be overlooked by your read-path models. Therefore, using an upload path classifier makes a lot of sense in these cases, and provides protection for these low prevalence issues.
- You need high precision filters to provide basic protection across all surfaces. If you only source “bad” content and leave the filtering to happen only at the ranking step, you will end up with not a lot of content to rank, reducing the effectiveness of your ranking algorithms. Therefore, it’s important for you to guarantee a good standard at sourcing to ensure most of the content you are sourcing is benign.
Conclusion: the combination of basic protection at sourcing, fine tuned filtering at ranking, and a read-path model allowed us to uphold a high quality standard of content on Explore. However, it’s important to always keep in mind that your protection at sourcing should always be high precision and low volume to avoid mistakes.
Learning 4: Tracking model performance is not only a good engineering practice, it’s also a must for user empathy.
This is something that goes beyond engineering, but it’s been a key to our work. When working on quality, it’s important for you to measure the performance of the models that you use in production. There are two reasons why:
- Having a precision and recall measurement calculated daily can help quickly identify when your model is decaying or when you have a problem in performance of one of the underlying features. It can also help alert you to a sudden change in the ecosystem.
- Understanding how your models perform can help you understand how to improve. A low precision model means your users may have a poor experience.
Having those metrics and a way to visualize the content labeled as “bad” has been a crucial improvement for our team. These dashboards allow our engineers to quickly identify any movement in metrics, and visualize the types of content violations required to improve the model, accelerating feature development and model iteration.
Conclusion: monitor your precision and recall curve daily, and make sure you understand the type of content being filtered out. That will help you identify issues, and quickly improve on your existing models.
Learning 5: Don’t use raw thresholds! Think about calibrating your model daily or filtering using percentiles.
We learned a lot by using raw thresholds as filters and adapted accordingly. Facebook is a complex ecosystem, and models have many underlying dependencies that could break and affect the upstream features of your model. This in turn can impact score distribution.
Overall, the issue with using raw thresholds is that they are too volatile. Any small change can cause unexpected fluctuations on surfaces, especially when suddenly you have a big metric movement from one day to the next.
As a solution, we recommend a calibration dataset to perform a daily calibration of your models, or a percentile filtering mechanism. We recently moved both our content filter and ranking frameworks to use percentiles, allowing us to have a more stable infrastructure, and we aim to establish a a calibration framework in the coming months.
Conclusion: use a percentile framework instead of raw thresholds, or consider calibrating your scores against a daily updated dataset.
Conclusions
Maintaining the safety of Instagram is imperative to our mission as a company, but it is a difficult area across our industry. For us, it’s critical to take novel approaches when tackling quality problems on our service, and not to rely on approaches learned in more traditional ML ranking projects. To wrap up, here are some of our key takeaways:
- Operationalizing a quality metric is important and you should always think if there are ways of relying more on machine learning to scale your human labels.
- Always think holistically about about how to apply quality enforcement on your ranking flow and try to think about integrating models on multiple layers of your system to achieve the best results.
- Always remember that the experience of those using your service is your most important priority, and make sure you have tools that visualize, monitor and calibrate the models you are using in production, to guarantee the best experience possible.
Want to learn more?
If you want to learn more about this work or are interested joining one of our engineering teams, please visit our careers page, follow us on Facebook or on Twitter.
Five things I learned about working on content quality at Instagram was originally published in Instagram Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]>Motivation
The motivation behind building Data Saver Mode was threefold:
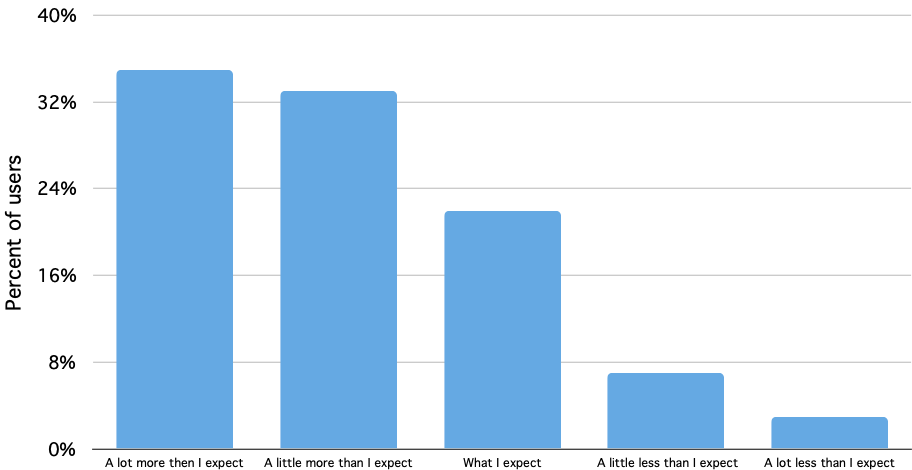
First, research suggested many people felt constrained while using Instagram because it consumed a big percentage of their data. We ran a survey in a few different countries (United States, Great Britain, India, Indonesia, Brazil, France, Germany, Japan, Argentina) in early 2018, which asked the question ‘How much data does Instagram use?’. More than 50% of respondents selected ‘a lot more than I expect’ or ‘a little more than I expect’. Furthermore, 30% of respondents said they run out of data every month, and 28% of people said they would use Instagram more if there was a Data Saver Mode feature.
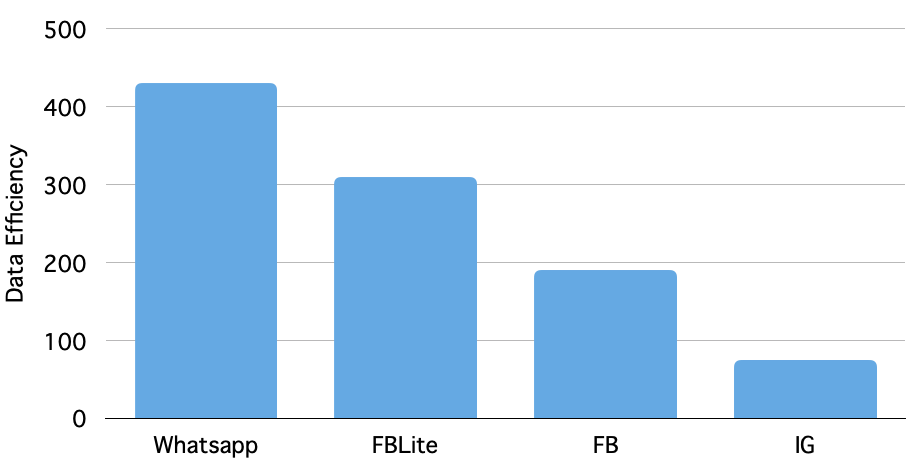
The second motivation was that we noticed Instagram would consume more data than we had initially desired. Intuitively, this made sense, as the more someone uses Instagram, the more content is consumed. However, we did note that overall data efficiency (i.e, time spent using the actual app for every megabyte of data consumed) could be improved. To illustrate, below you can see how IG data efficiency ranked below than that of Facebook, Facebook Lite, and WhatsApp.
The third motivation was Android’s Native Data Saver feature, which was starting to gain traction among users. From Android 7.0 onwards, people can enable Data Saver for the entire device. When enabled, the system will block background use of cellular data, as well as signaling the app to consume less data while in the foreground. We have used IG while having native Data Saver mode on, and because our app is media-heavy, this native implementation causes a disruptive user experience, as photos and videos would either load very slowly, or simply not load at all.
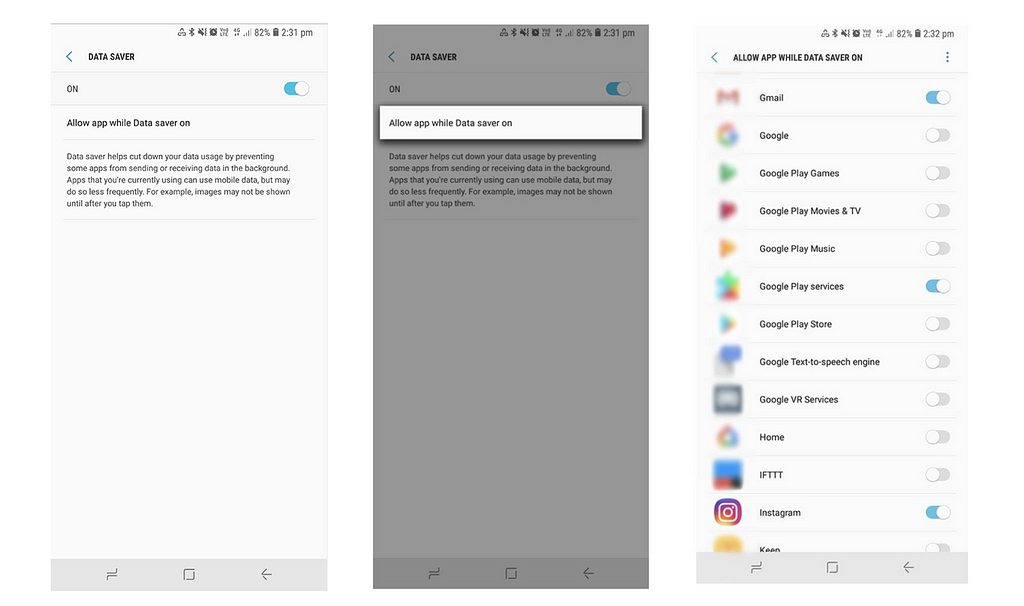
Google provides APIs to check whether someone has turned on Data Saver at the system level, but has not provided a way for developers to change native Data Saver implementation at the application level [1]. People can also restrict apps in native Data Saver, so if someone enables Data Saver, they could restrict IG and use our custom Data Saver Mode instead, for a less disruptive user experience.
Levers
Below are the levers that we used for our Data Saver implementation:
1. Disabling Video Prefetch
We currently prefetch upcoming videos in a person’s feed and stories viewer so that the videos are ready to play when a user arrives to a video on screen. We hypothesized that this behavior uses more data, especially if the user does not end up scrolling to the upcoming videos later in the feed. Thus, we can disable video prefetch so that we are only fetching video content when the user has paused their scrolling at a video, indicating they are watching the video. This would reduce data usage since a person may not want to watch all videos they are scrolling through in their feed.
2. Disabling Video Auto Play
We currently automatically play all videos when they become visible on screen without user interaction. We hypothesized that this behavior uses more data, especially if the user does not intend to watch every single video that they scroll through. Thus, we can disable autoplay, and display a play button to allow users to manually play videos. This is a more drastic version of disabling video prefetch, since it requires extra user interaction to engage with a video media.
3. Reducing media quality/resolution
Currently, we decide image and video resolution based on constraints such as a user’s connectivity and bandwidth. Rendering high resolution media is going to consume more data than low resolution media, given the larger file size. This can matter quite a bit for users in unique connectivity situations, which can be difficult to detect at the application level. For example, people using pocket mobile will appear as if they are on wifi, when in reality, they are using cellular data. Thus, we can provide a setting for users to decide at what connectivity setting they want to view higher resolution media. This allows users to still browse the content they care about, without using too much data.
The tradeoff with enabling the above three levers is that we want to ensure users still have a consistent browsing experience with reasonable media loading time, given that Instagram is a media-heavy app.
Approach
At Instagram, we understand that a meaningful portion of our users are in markets where connectivity can only be accessed through mobile cellular data, as opposed to at-home connectivity (i.e, WiFi). Demand for affordable connectivity has grown, so the cost of data becomes a key factor in a user’s decision to engage with online content. While we can primarily look at emerging markets, there are also industrial countries where the high cost of data means that a considerable part of the population is also data-conscious. Taking all this into account, we tested in Indonesia, India, Argentina, Germany and France. The team tested several different variants of Data Saver with the above three parameters, and with variants that displayed user-visible options for disabling autoplay and controlling media quality.
During this first country test, we found that disabling video prefetch provided a good balance of reducing data usage while still providing a reasonable browsing experience. Predictably, by not auto-playing video content, people consumed less video. However, we also saw that people valued explicit control over media quality and auto-play.
We found that there were two variants that tied as best performing test variants:
- Disabling video prefetching. Option of choosing when to receive High Resolution Media (“Never”,
“only on Wi-Fi”, or “both on Wi-Fi and cellular”), with selection defaulted to “only on Wi-Fi” - Disabling video prefetching. Option of choosing when to receive High Resolution Media (“Never”,
“only on Wi-Fi”, or “both on Wi-Fi and cellular”), with selection defaulted to “both on Wi-Fi and cellular”
The variants are the same, the only difference is that the default selection is different (“only on Wi-Fi” and “both on Wi-Fi and cellular”) for the High Resolution Media option. Each performed better in certain countries, so we decided we would do another country test in Canada and Great Britain (as previous research had shown these countries are also data conscious). This informed our decision to finally test globally and launch to everyone.
For our global launch, we decided to keep the High Resolution Media user option and defaulted it to “only on Wi-Fi”.
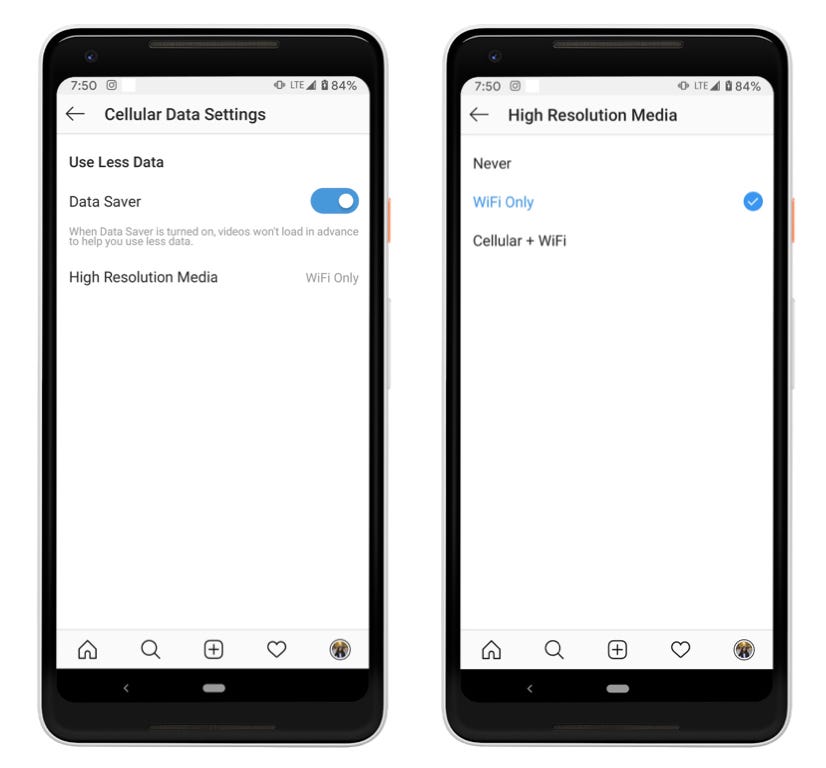
User Impact
For our test in CA & GB, the best performing version was the one that disabled video prefetching and defaulted to high resolution media on both Wi-Fi and Cellular. Note that as this is an opt-in feature and only ~10% of people in the test group opted in, so the results we saw in our A/B test were quite diluted. Nonetheless, we saw a sizable decrease in data usage while on cellular. We also saw increases in number of interactions, number of media created, and other engagement metrics. These were significant wins, especially when you take into account that only 10% of users in the test group were driving them. Finally, we only saw regressions in video loading metrics, which we expected from our disabling of video prefetching, but they were not too big.
In our CA & GB test, 1.6% of users in the default high resolution media only on Wi-Fi switched to high resolution media on both Wi-Fi and Cellular, and 10% of users in the default high resolution media on both Wi-Fi and Cellular switched to high resolution media only on Wi-Fi. Admittedly, we are not entirely certain as to why we saw this large difference, but one of our hypotheses is that people who are very conscious about their data consumption are more likely to actively employ options to conserve data.
For our global test, the best performing version was the one that disabled video prefetching and defaulted to high resolution media only on Wi-Fi. This test was done through a less targeted lens, but we still saw improvements in engagement and data consumption on cellular. Given all of these positive results, we concluded this feature would be very beneficial for data-constrained users and we shipped it globally in June 2019.
Appendix
[1] https://developer.android.com/training/basics/network-ops/data-saver
The Data Saver Mode feature wouldn’t have been possible without the collaboration of research, data, engineering, and product. Thanks to Elisa Lou, who co-authored this post with me and is the engineer who worked on Data Saver Mode — couldn’t have done it without you. Thanks to Kat Li, Jeff LaFlam, Michael Midling, Colin Shepherd and many more.
If you want to learn more about this work or are interested in joining one of our engineering teams, please visit our careers page, follow us on Facebook or on Twitter.
Instagram Data Saver Mode was originally published in Instagram Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]>Over half of the Instagram community visits Instagram Explore every month to discover new photos, videos, and Stories relevant to their interests. Recommending the most relevant content out of billions of options in real time at scale introduces multiple machine learning (ML) challenges that require novel engineering solutions.
We tackled these challenges by creating a series of custom query languages, lightweight modeling techniques, and tools enabling high-velocity experimentation. These systems support the scale of Explore while boosting developer efficiency. Collectively, these solutions represent an AI system based on a highly efficient 3-part ranking funnel that extracts 65 billion features and makes 90 million model predictions every second.
In this blog post, we’re sharing the first detailed overview of the key elements that make Explore work, and how we provide personalized content for people on Instagram.
Developing foundational building blocks of Explore
Before we could execute on building a recommendation engine that tackles the sheer volume of photos and videos uploaded daily on Instagram, we developed foundational tools to address three important needs. We needed the ability to conduct rapid experimentation at scale, we needed to obtain a stronger signal on the breadth of people’s interests, and we needed a computationally efficient way to ensure that our recommendations were both high quality and fresh. These custom techniques were key to achieving our goals:
Iterating quickly with IGQL: A new domain-specific language
Building the optimal recommendation algorithms and techniques is an ongoing area of research in the ML community, and the process of choosing the right system can vary widely depending on the task. For instance, while one algorithm may effectively identify long-term interests, another may perform better at identifying recommendations based on recent content. Our engineering team iterates on different algorithms, and we needed a way for us to both try out new ideas efficiently and apply the promising ideas to large-scale systems easily without worrying too much about computational resource implications like CPU and memory usage. We needed a custom domain specific meta-language that provides the right level of abstraction and assembles all algorithms into one place.
To solve this, we created and shipped IGQL, a domain-specific language optimized for retrieving candidates in recommender systems. Its execution is optimized in C++, which helps minimize both latency and compute resources. It’s also extensible and easy to use when testing new research ideas. IGQL is both statically validated and high-level. Engineers can write recommendation algorithms in a Python-like way and execute fast and efficiently in C++.
user
.let(seed_id=user_id)
.liked(max_num_to_retrieve=30)
.account_nn(embedding_config=default)
.posted_media(max_media_per_account=10)
.filter(non_recommendable_model_threshold=0.2)
.rank(ranking_model=default)
.diversify_by(seed_id, method=round_robin)
In the code sample above, you can see how IGQL provides high readability even for engineers who haven’t worked extensively in the language. It helps assemble multiple recommendation stages and algorithms in a principled way. For example, we can optimize the ensemble of candidate generators by using a combiner rule in query to output a weighted blend of several subquery outputs. By tweaking their weights, we can find the combination that results in the best user experience.
IGQL makes it simple to perform tasks that are common in complex recommendation systems, such as building nested trees of combiner rules. IGQL lets engineers focus on ML and business logic behind recommendations as opposed to logistics, like fetching the right quantity of candidates for each query. It also provides a high degree of code reusability. For instance, applying a ranker is as simple as adding a one-line rule to our IGQL query. It’s trivial to add it in multiple places, like ranking accounts and ranking media posted by those accounts.
Account embeddings for personalized ranking inventory
People publicly share billions of high quality pieces of media on Instagram that are eligible inventory for Explore. It’s challenging to maintain a clear and ever-evolving catalog-style taxonomy for the large variety of interest communities on Explore — with topics varying from Arabic calligraphy to model trains to slime. As a result, content-based models have difficulty grasping such a variety of interest-based communities.
Because Instagram has a large number of interest-focused accounts based on specific themes — such as Devon rex cats or vintage tractors — we created a retrieval pipeline that focuses on account-level information rather than media-level. By building account embeddings, we’re able to more efficiently identify which accounts are topically similar to each other. We infer account embeddings using ig2vec, a word2vec-like embedding framework. Typically, the word2vec embedding framework learns a representation of a word based on its context across sentences in the training corpus. Ig2vec treats account IDs that a user interacts with — e.g., a person likes media from an account — as a sequence of words in a sentence.
By applying the same techniques from word2vec, we can predict accounts with which a person is likely to interact in a given session within the Instagram app. If an individual interacts with a sequence of accounts in the same session, it’s more likely to be topically coherent compared with a random sequence of accounts from the diverse range of Instagram accounts. This helps us identify topically similar accounts.
We define a distance metric between two accounts — the same one used in embedding training — which is usually cosine distance or dot product. Based on this, we do a KNN lookup to find topically similar accounts for any account in the embedding. Our embedding version covers millions of accounts, and we use Facebook’s state-of-the-art nearest neighbor retrieval engine, FAISS, as the supporting retrieval infrastructure.
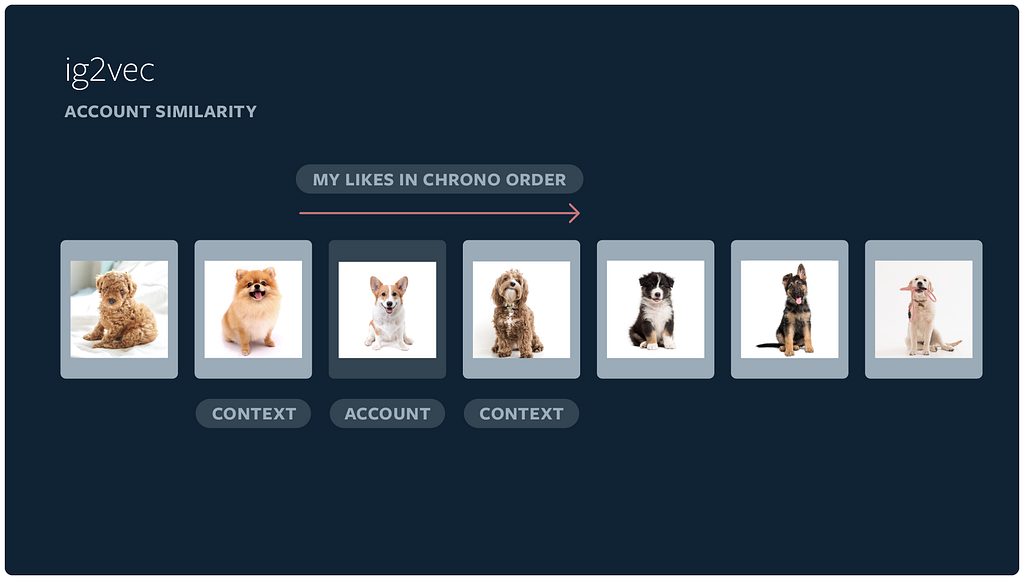
For each version of the embedding, we train a classifier to predict a set of accounts’ topic solely based on the embedding. By comparing the predicted topics with human-labeled topics for accounts in a hold-out set, we can assess how well the embeddings capture topical similarity.
Retrieving accounts that are similar to those that a particular person previously expressed interest in helps us narrow down to a smaller, personalized ranking inventory for each person in a simple yet effective way. As a result, we are able to utilize state-of-the-art and computationally intensive ML models to serve every Instagram community member.
Preselecting relevant candidates by using model distillation
After we use ig2vec to identify the most relevant accounts based on individual interests, we need a way to rank these accounts in a way that’s fresh and interesting for everyone. This requires predicting the most relevant media for each person every time they scroll the Explore page.
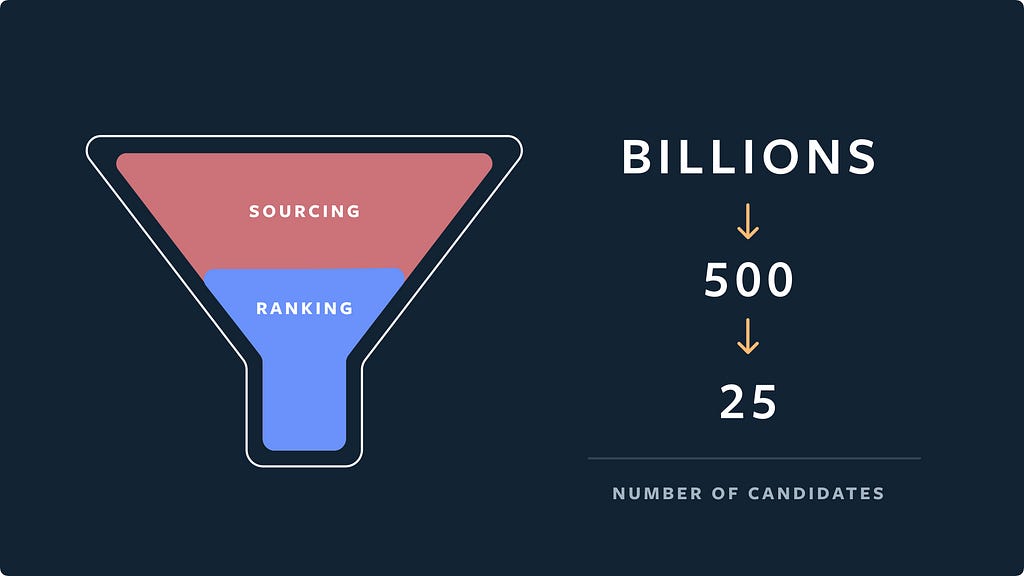
For instance, evaluating even just 500 media pieces through a deep neural network for every scrolling action requires a large amount of resources. And yet the more posts we evaluate for each user, the higher the possibility we have of finding the best, most personalized media from their inventory.
In order to be able to maximize the number of media for each ranking request, we introduced a ranking distillation model that helps us preselect candidates before using more complex ranking models. Our approach is to train a super-lightweight model that learns from and tries to approximate our main ranking models as much as possible. We record the input candidates with features, as well as outputs, from our more complicated ranking models. The distillation model is then trained on this recorded data with a limited set of features and a simpler neural network model structure to replicate the results. Its objective function is to optimize for NDCG ranking (a measure of ranking quality) loss over main ranking model’s output. We use the top-ranked posts from the distillation model as the ranking candidates for the later-stage high-performance ranking models.
Setting up the distillation model’s mimicry behavior minimizes the need to tune multiple parameters and maintain multiple models in different ranking stages. Leveraging this technique, we can efficiently evaluate a bigger set of media to find the most relevant media on every ranking request while keeping the computational resources under control.
How we built Explore
After creating the key building blocks necessary to experiment easily, identify people’s interests effectively, and produce efficient and relevant predictions, we had to combine these systems together in production. Utilizing IGQL, account embeddings, and our distillation technique, we split the Explore recommendation systems into two main stages: the candidate generation stage (also known as sourcing stage) and the ranking stage.
Candidate Generation
First, we leverage accounts that people have interacted with before (e.g., liked or saved media from an account) on Instagram to identify which other accounts people might be interested in. We call them the seed accounts. The seed accounts are usually only a fraction of the accounts on Instagram that are about similar or the same interests. Then, we use account embeddings techniques to identify accounts similar to the seed accounts. Finally, based on these accounts, we’re able to find the media that these accounts posted or engaged with.
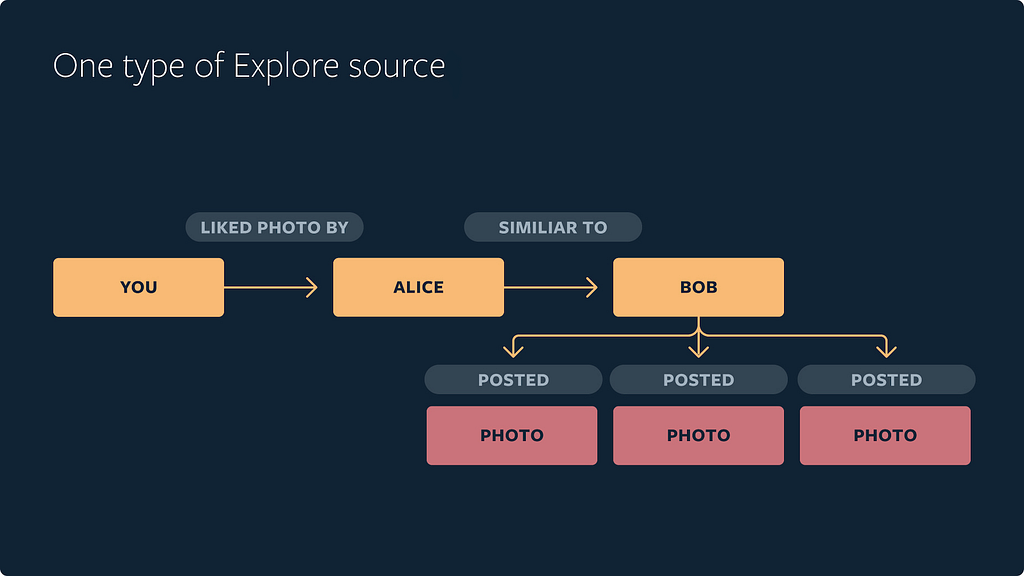
There are many different ways people can engage with accounts and media on Instagram (e.g., follow, like, comment, save, and share). There are also different media types (e.g., photo, video, Stories, and Live), which means there are a variety of sources we can construct using a similar scheme. Leveraging IGQL, the process becomes very easy — different candidate sources are just represented as different IGQL subqueries.
With different types of sources, we are able to find tens of thousands of eligible candidates for the average person. We want to make sure the content we recommend is both safe and appropriate for a global community of many ages on Explore. Using a variety of signals, we filter out content we can identify as not being eligible to be recommended before we build out eligible inventory for each person. In addition to blocking likely policy-violating content and misinformation, we leverage ML systems that help detect and filter content like spam.
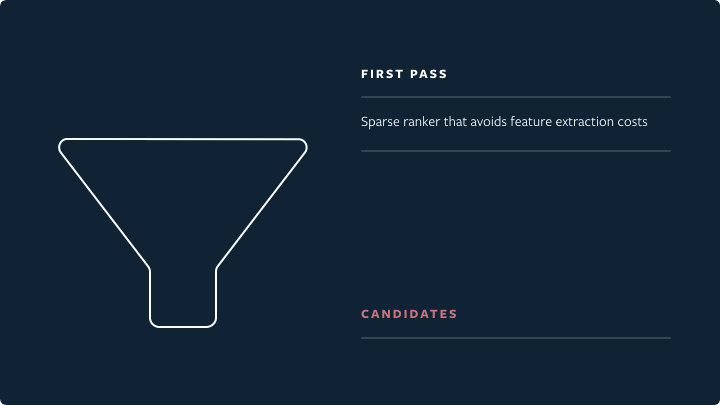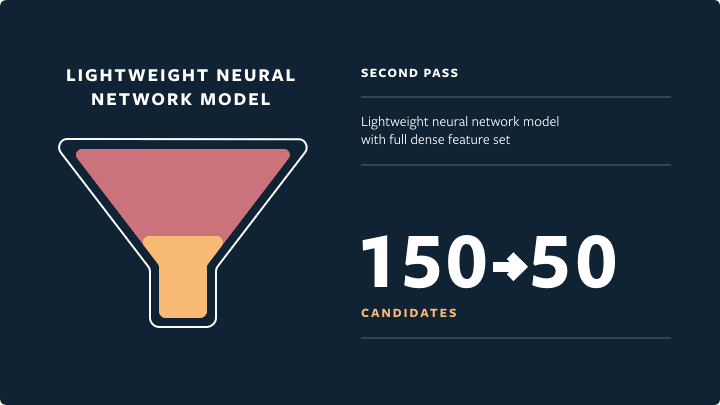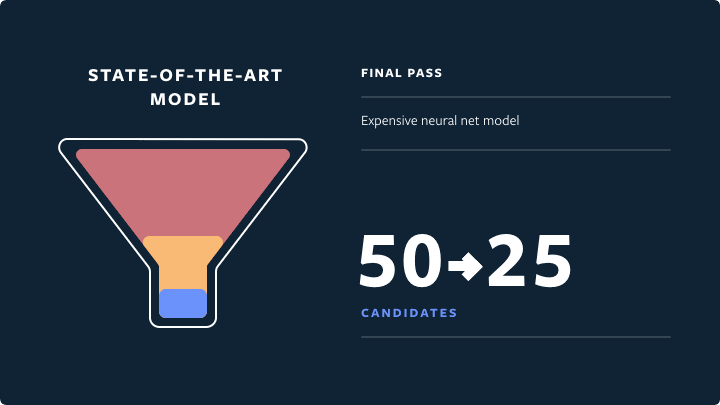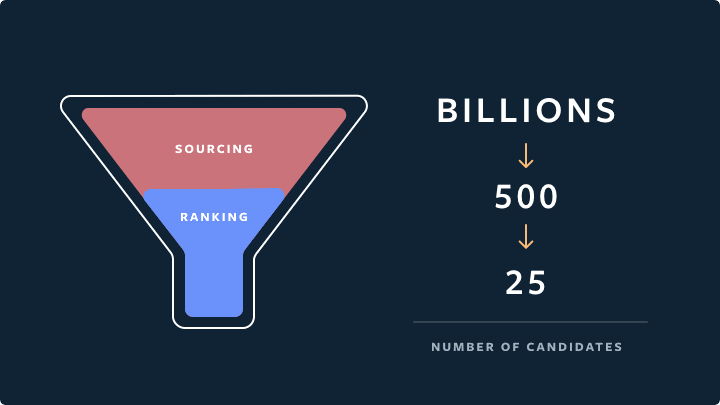
Then, for every ranking request, we identify thousands of eligible media for an average person, sample 500 candidates from the eligible inventory, and then send the candidates downstream to the ranking stage.
Ranking candidates
With 500 candidates available for ranking, we use a three-stage ranking infrastructure to help balance the trade-offs between ranking relevance and computation efficiency. The three ranking stages we have are as follows:
- First pass: the distillation model mimics the combination of the other two stages, with minimal features; picks the 150 highest-quality and most relevant candidates out of 500.
- Second pass: a lightweight neural network model with full set of dense features; picks the 50 highest-quality and most relevant candidates.
- Final pass: a deep neural network model with full set of dense and sparse features. Picks the 25 highest-quality and most relevant candidates (for the first page of Explore grid).
If the first-pass distillation model mimics the other two stages in ranking order, how do we decide the most relevant content in the next two stages? We predict individual actions that people take on each piece of media, whether they’re positive actions such as like and save, or negative actions such as “See Fewer Posts Like This” (SFPLT). We use a multi-task multi-label (MTML) neural network to predict these events. The shared multilayer perceptron (MLP) allows us to capture the common signals from different actions.
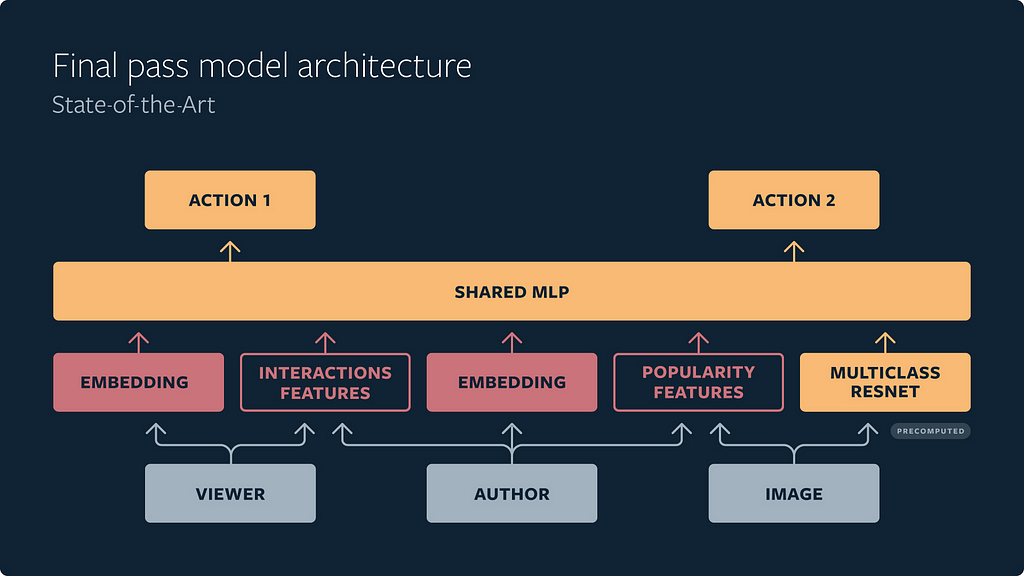
We combine predictions of different events using an arithmetic formula, called value model, to capture the prominence of different signals in terms of deciding whether the content is relevant. We use a weighted sum of predictions such as [w_like * P(Like) + w_save * P(Save) — w_negative_action * P(Negative Action)]. If, for instance, we think the importance of a person saving a post on Explore is higher than their liking a post, then the weight for the save action should be higher.
We also want Explore to be a place where people can discover a rich balance of both new interests alongside existing interests. We add a simple heuristic rule into value model to boost the diversity of content. We down-rank posts from the same author or same seed account by adding a penalty factor, so you don’t see multiple posts from the same person or the same seed account in Explore. This penalty increases as you go down the ranked batch and encounter more posts from the same author.
We rank the most relevant content based on the final value model score of each ranking candidate in a descendant way. Our offline replay tool — along with Bayesian optimization tools — helps us tune the value model efficiently and frequently as our systems evolve.
An ongoing ML challenge
One of the most exciting parts of building Explore is the ongoing challenge of finding new and interesting ways to help our community discover the most interesting and relevant content on Instagram. We’re continuously evolving Instagram Explore, whether by adding media formats like Stories and entry points to new types of content, such as shopping posts and IGTV videos.
The scale of both the Instagram community and inventory requires enabling a culture of high-velocity experimentation and developer efficiency to reliably recommend the best of Instagram for each person’s individual interests. Our custom tools and systems have given us a strong foundation for the continuous learning and iteration that are essential to building and scaling Instagram Explore.
If you want to learn more about this work or are interested joining one of our engineering teams, please visit our careers page, follow us on Facebook or on Twitter.
Written by Ivan Medvedev, Haotian Wu, and Taylor Gordon.
Powered by AI: Instagram’s Explore recommender system was originally published in Instagram Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]>
How did you become an engineer?
When working on course projects during my undergrad and grad study, I felt the passion for solving coding problems, which was the main motivation to apply for an engineering position after graduation. After joining Facebook, I was still motivated to solve practical problems every day and learn new skills/knowledge, which affirmed my career choice.
What was your first coding language?
C was my first coding language back to school days. Objective-C was my first coding language at my full-time work at Facebook.
What do you listen to while you work?
All kinds of piano songs which can help me keep focused. For example, Ghibli’s relaxing piano pieces are good.
What do you do when you get stuck on a problem?
I will usually take a short walk to the nearest snack kitchen and look for some snacks. I feel walking and eating can help me think better.
Tell us about your favorite project at Instagram?
- My favorite project at Instagram was the work we did to combat drug and firearms sales, together with the Facebook Community Integrity team. It was one of our first projects collaborating with this team. The project itself was exciting: we adopted a new machine learning model technology, and we shipped several models to production.
- The part I valued most was the amazing collaboration experience across different teams, including cross-functional partners such as privacy, policy, and legal.
What makes working at Instagram unique?
- Instagram has fewer engineers compared to Facebook (the app), while being responsible for a product as important as other FB products. So it’s quite common for Instagram engineers to be responsible for large scope of work.
- Instagram has a flatter management structure. There are more opportunities to communicate or present directly to org leads. Bigger scope and more direct/transparent communication make me feel stronger ownership and fulfillment of my projects and work.
How would you describe the engineering culture at Instagram?
- We valued user experience and user privacy highly. We treated all users’ experience very seriously. A lot of projects were driven by user reports or feedback. We also worked very closely with legal, policy, and privacy. Every project or product change needs to be extremely carefully discussed and reviewed by these experts.
- On our team, we leave 20% of our time to deal with ad-hoc or unexpected issues.
- A very respectful and supportive work environment. We value the culture of “Be the Ally” very much in our org. I personally benefit a lot and also contribute to this valuable culture in my daily work.
- A Data-driven approach. We valued data analysis highly in Instagram. Most of the projects have very analytical goals. We tracked metrics closely in our daily work.
- Fun and optimistic and positive working atmosphere. People here are very good at bringing fun into work. You can hear a lot of fun stories or jokes during Q&A or meetings. Even during the intense times, you can still see people making fun with each other and encouraging each other (work was still completed with high efficiency and quality).
What makes you excited about coming into work every day?
Exciting projects and brilliant colleagues.
Your favorite place to eat in the city?
A lot of Chinese restaurants :)
What is your favorite thing to eat at the office?
Pocky in strawberry flavor
What’s your favorite Instagram account?
@kuviabear, I like following the sweet daily life of cute Kuvia!
Tell us about your happiest day at Instagram.
- To be honest, it’s hard to choose which was the happiest day at Instagram. I still remember the first day I walked into our building and sat with my team. I was so impressed by all the decorations inside the building, also the sweet corner views from my desk.
- I also remember all the relaxing casual conversations that happened in micro-kitchen during or after happy hours, so many fun jokes and laughs.
- And there are also intense but exciting days near deadlines, when everyone was fighting for the same goal within such a short amount of time. I remember how thrilled and excited the whole team was when we hit our goal or launched the projects.
What is one of the best things you learned while working at Instagram?
I gained a lot of valuable experience in coordination and collaborations across teams/roles in Instagram. I would say Instagram may provide the best example on how engineers and cross-function team members, such as product, legal, privacy expert, work together among the whole company. And my team has many cross team partners, most of them are located remotely. The projects I worked on provided me a lot of great opportunities to learn how to work with different teams and people closely and smoothly.
What does your desk setup look like?
One monitor and one Apple Mac Pro (I got it for iOS development and I probably should return it now 😂).

What was your favorite offsite?
Well-being Team Offsite at Clay By The Bay. We had a great day on learning and practicing working with clay. And my favorite part was that we received our “work” as the outcome :P.

If you want to learn more about this work or are interested joining one of our engineering teams, please visit our careers page, follow us on Facebook or on Twitter.
10 Questions with Shupin Mao, Well-being tech lead was originally published in Instagram Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]>Code size and execution optimizations
In parts 1–3 we covered various ways that we optimized the loading patterns of the critical path static resources and data queries. However there is another key area we haven’t covered yet that’s crucial to improving web application performance, particularly on low-end devices — ship less code to the user — in particular, ship less JavaScript.
This might seem obvious, but there are a few points to consider here. There’s a common assumption in the industry that the size of the JavaScript that gets downloaded over the network is what’s important (i.e. the size post-compression), however we found that what’s really important is the size pre-compression as this is what has to be parsed and executed on the user’s device, even if it’s cached locally. This becomes particularly true if you have a site with many repeat users (and subsequent high browser cache hit rates) or users accessing your site on mobile devices. In these cases the parsing and execution performance of JavaScript on the CPU becomes the limiting factor rather than the network download time. For example, when we implemented Brotli compression for our JavaScript assets, we saw a nearly 20% reduction of post-compression size across the wire, but NO statistically significant reduction in the overall page load times as seen by end users.
On the other hand, we’ve found reductions in pre-compression JavaScript size have consistently led to performance improvements. It’s also worth making a distinction between JavaScript that is executed on the critical path and JavaScript that is dynamically imported after the main page has completed. While ideally it would be nice to reduce the total amount of JavaScript in an application, a key thing to optimize in the short term is the amount of eagerly executed JavaScript on the critical path (we track this with a metric we call Critical Bytes Per Route). Dynamically imported JavaScript that lazy loads is generally not going to have as significant an effect on page load performance, so it’s a valid strategy to move non-visible or interaction dependent UI components out of the initial page bundles and into dynamically imported bundles.
Refactoring our UI to reduce the amount of script on the critical path is going to be essential to improving performance in the long term — but this is a significant undertaking which will take time. In the short-term we worked on a number of projects to improve the size and execution efficiency of our existing code in ways that are largely transparent to product developers and require little refactoring of existing product code.
Inline requires
We bundle our frontend web assets using Metro (the same bundler used by React Native) so we get access to inline-requires out of the box. Inline-requires moves the cost of requiring/importing modules to the first time when they are actually used. This means that you can avoid paying execution cost for unused features (though you’ll still pay the cost of downloading and parsing them) and you can better amortize the execution cost over the application startup, rather than having a large amount of upfront computation.
To see how this works in practice, lets take the following example code:
Using inline requires this would get transformed into something like the following (you’ll find these inline requires by searching for r(d[ in the Instagram JS source in your browser developer tools)
As we can see, it essentially works by replacing the local references to a required module with a function call to require that module. This means that unless the code from that module is actually used, the module is never required (and therefore never executed). In most cases this works extremely well, but there are a couple of edge cases to be aware of that can cause problems — namely modules with side effects. For example:
Without inline requires, Module C would output {'foo':'bar'}, but when we enable inline-requires, it would output undefined, because B has an implicit dependency on A. This is a contrived example, but there are other real world cases where this can have effects i.e. what if a module does some logging as a part of its initialization - enabling inline-requires could cause this logging to stop happening. This is mostly preventable through linters that check for code that executes immediately at the module scope level, but there were some files we had to blacklist from this optimization such as runtime polyfills that need to execute immediately. After experimenting enabling inline requires across the codebase we saw an improvement in our Feed TTI (time to interactive) by 12% and Display Done by 9.8%, and decided that dealing with some of these minor edge cases was worth it for the performance improvements.
Serving ES2017 bundles to modern browsers
One of the primary drivers that drove the adoption of compiler/transpiler tools like Babel was allowing developers to use modern JavaScript coding idioms but still have their applications work in browsers that lacked native support for these latest language features. Since then a number of other important use-cases for these tools arose including compile-to-js languages like Typescript and ReasonML, language extensions such as JSX and Flow type annotations, and build time AST manipulations for things like internationalization. Because of this, it’s unlikely that this extra compilation step is going to go disappear from frontend development workflows any time soon. However, with that said it’s worth revisiting if the original purpose for doing this (cross browser compatibility) is still necessary in 2019.
ES2015 and more recent features like async/await are now well supported across recent versions of most major browsers, so directly serving JavaScript containing these newer features is definitely possible — but there are two key questions that we had to answer first:
- Would enough users be able to take advantage of this to make the extra build complexity worthwhile (as you’d still need to maintain the legacy transpiling step for older browsers),
- And what (if any) are the performance advantages of shipping ES2015+ features
To answer the first question we first had to determine which features we were going to ship without transpiling/polyfilling and how many build variants we wanted to support for the different browsers. We settled on having two builds, one that would require support for ES2017 syntax, and a legacy build that would transpile back to ES5 (in addition we also added an optional polyfill bundle that would only be added for legacy browsers that lacked runtime support for more recent DOM API’s). Detecting support for these groups is done via some basic user-agent sniffing on the server side which ensures there is no runtime cost or extra roundtrip time from doing client-side detection of which bundles to load.
With this in mind, we ran the numbers and determined that 56% of users to instagram.com are able to be served the ES2017 build without any transpiling or runtime polyfills, and considering that this percentage is only going to go up over time — it seems like its worth supporting two builds considering the number of users able to utilize it.
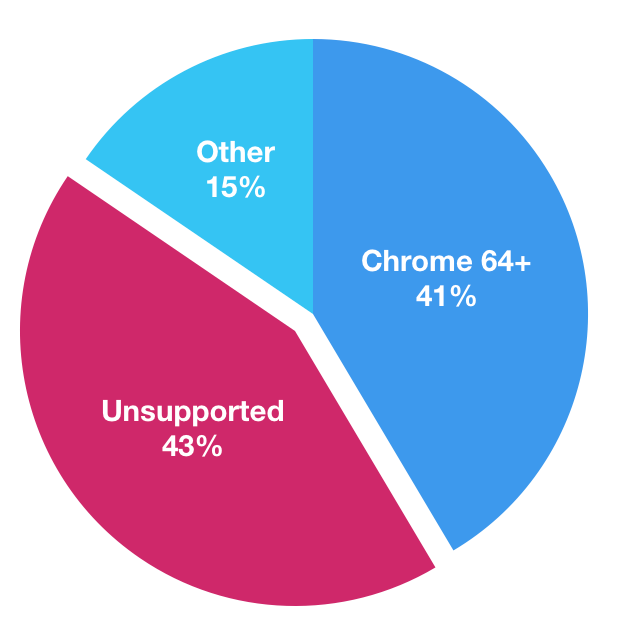
As for the second question — what are the performance advantages of shipping ES2017 directly — lets start by looking at what Babel actually does to transpile some common constructs back to ES5. In the left hand column is the ES2017 code, and on the right is the transpiled ES5 compatible version.
Class (ES2017 vs ES5)
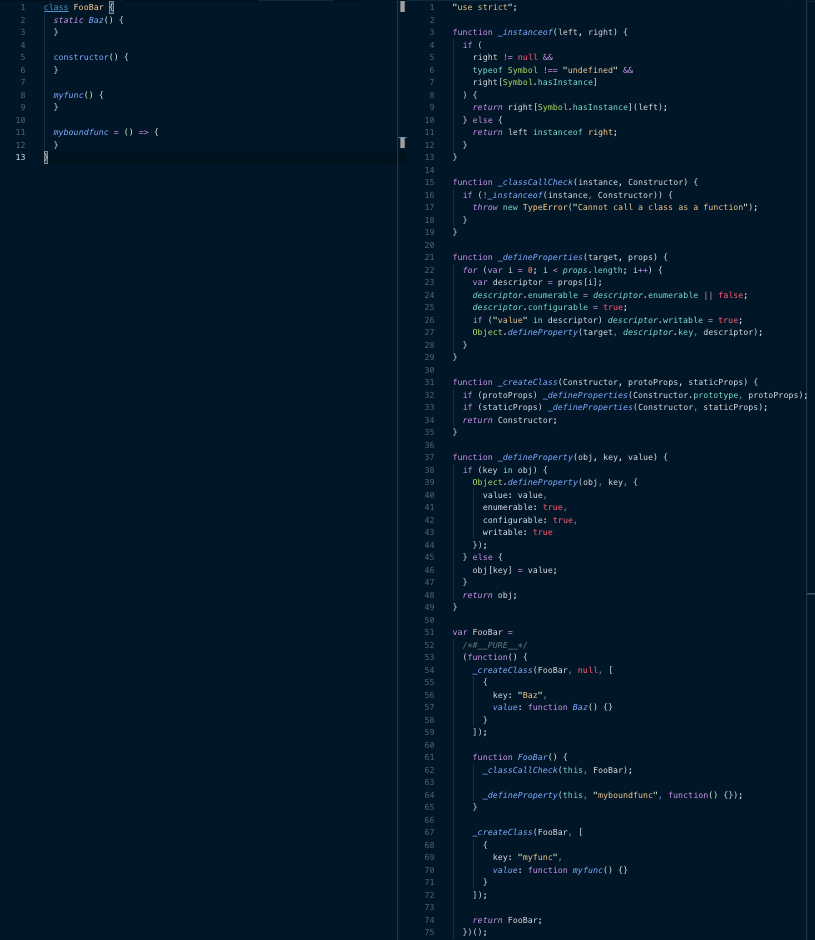
Async/Await (ES2017 vs ES5)
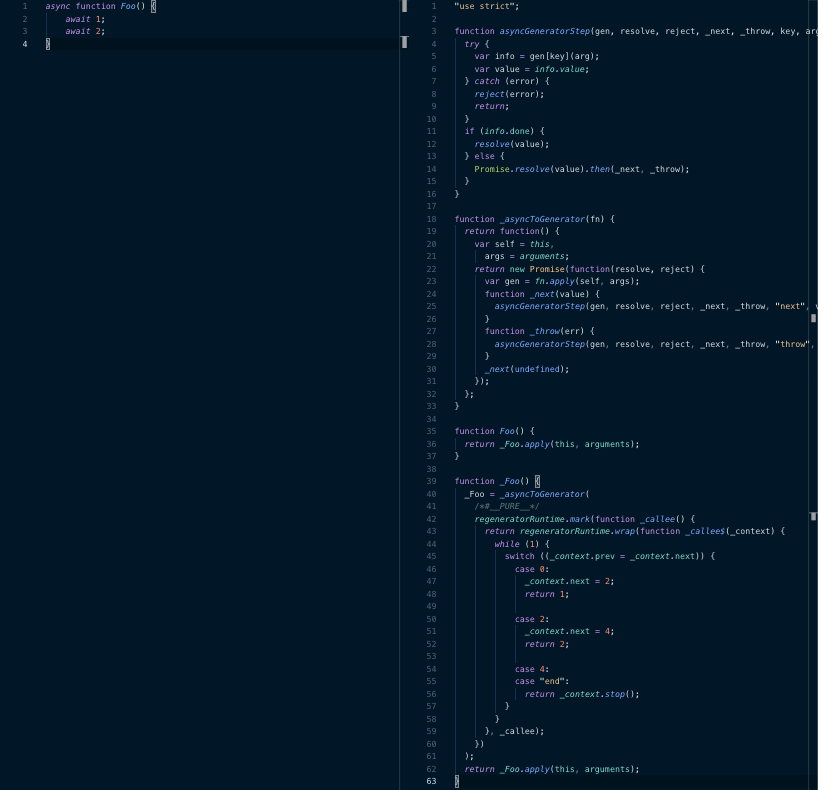
Arrow functions (ES2017 vs ES5)

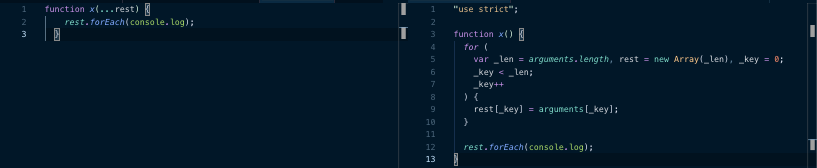
Rest parameters (ES2017 vs ES5)
Destructuring assignment (ES2017 vs ES5)
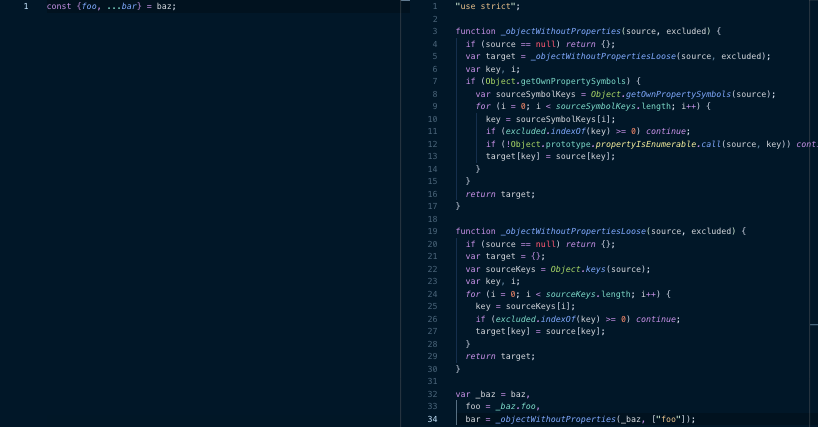
From this we can see that there is a considerable size overhead in transpiling these constructs (even if you amortize the cost of some of the runtime helper functions over a large codebase). In the case of Instagram, we saw a 5.7% reduction in the size of our core consumer JavaScript bundles when we removed all ES2017 transpiling plugins from our build. In testing we found that the end-to-end load times for the feed page improved by 3% for users who were served the ES2017 bundle compared with those who were not.
Still a long way to go
While the progress that has been made so far is impressive, the work we’ve done so far represents just the beginning. Theres still a huge amount of room left for improvement in areas such as Redux store/reducer modularization, better code splitting, moving more JavaScript execution off the critical path, optimizing scroll performance, adjusting to different bandwidth conditions, and more.
If you want to learn more about this work or are interested joining one of our engineering teams, please visit our careers page, follow us on Facebook or on Twitter.
Making instagram.com faster: Code size and execution optimizations (Part 4) was originally published in Instagram Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]>We’ve run into a few pain points working with Python at that scale and speed. This article takes a look at a few that we imagine might impact others as well.
Consider this innocuous-looking sample module:
import re
from mywebframework import db, route
VALID_NAME_RE = re.compile("^[a-zA-Z0-9]+$")@route('/')
def home():
return "Hello World!"class Person(db.Model):
name: str
When someone imports this module, what code will run?
- We’ll run a bunch of regex code to compile that string to a pattern object.
- We’ll run the @route decorator. Based on what we see here, we can assume that it's probably registering this view in some url mapping. This means that just by importing this module, we're mutating global state somewhere else.
- We’re going to run all the code inside the body of the Person class, which can include arbitrary code. And the Model base class might have a meta-class or an __init_subclass__ method, which is still more arbitrary code we might be running at import.
Pain area one: slow startup and reload
The only line of code in this module that (probably) doesn’t run on import is return "Hello World!", but we can't even say that for sure! So by just importing this simple eight line module (not even doing anything with it yet!), we are probably running hundreds, if not thousands of lines of Python code, not to mention modifying a global URL mapping somewhere else in our program.
So what? This is part of what it means for Python to be a dynamic, interpreted language. This lets us do all kinds of useful meta-programming. What's wrong with that?
Nothing is wrong with it, when you're working with relatively small codebases and teams, and you can guarantee some level of discipline in how you use these features. But some aspects of this dynamism can become a concern when you have millions of lines of code worked on by hundreds of developers, many of whom are new to Python.
For example, one of the great things about Python is how fast you can iterate with it: make a change and see the result, no compile needed! But with a few million lines of code (and a messy dependency graph), that advantage starts to turn sour.
Our server startup takes over 20s, and sometimes regresses to more like a minute if we aren't paying attention to keeping it optimized. That means 20-60 seconds between a developer making a change and being able to see the results of that change in their browser, or even in a unit test. This, unfortunately, is the perfect amount of time to get distracted by something shiny and forget what you were doing. Most of that time is spent literally just importing modules, creating function and class objects.
In some ways, that's no different from waiting for another language to compile. But typically compilation can be incremental: you can just recompile the stuff you changed and things that directly depend on it, so many smaller changes can compile quickly. But in Python, because imports can have arbitrary side effects, there is no safe way to incrementally reload our server. No matter how small the change, we have to start from scratch every time, importing all those modules, re-creating all those classes and functions, re-compiling all of those regular expressions, etc. Usually 99% of the code hasn't changed since last time we reloaded the server, but we have to re-do all that slow work anyway.
In addition to slowing down developers, this is a significant amount of wasted compute in production, too, since we continuously deploy and are thus reloading the site on production servers constantly all day long.
So that's our first pain point: slow server startup and reload due to lots of wasted repeat work at import time.
Pain area two: unsafe import side effects
Here’s another thing we often find developers doing at import time: fetching configuration from a network configuration source.
MY_CONFIG = get_config_from_network_service()
In addition to slowing down server startup even further, this is dangerous, too. If the network service is not available, we won’t just get a runtime error failing certain requests, our server will fail to start up.
Let’s make this a bit worse, and imagine that someone has added some import-time code in another module that does some critical initialization of the network service. They don’t know where to put this code, so they stick it in some module that happens to get imported pretty early on. Everything works, so they move on.
But then someone else comes along, adds an innocuous import in some other part of the codebase, and through an import chain twelve modules deep, it causes the config-fetching module to now be imported before the one that does the initialization.
Now we’re trying to use the service before it’s initialized, so it blows up. In the best case, where the interaction is fully deterministic, this could still result in a developer tearing their hair out for an hour or two trying to understand why their innocent change is causing something unrelated to break. In a more complex case where it’s not fully deterministic, this could bring down production. And there’s no obvious way to generically lint against or prevent this category of issue.
The root of the problem here is two factors that interact badly:
1) Python allows modules to have arbitrary and unsafe import side effects, and
2) the order of imports is not explicitly determined or controlled, it’s an emergent property of the imports present in all modules in the entire system (and can also vary based on the entry point to the system).
Pain area 3: mutable global state
Let’s look at one more category of common errors.
def myview(request):
SomeClass.id = request.GET.get("id")
Here we’re in a view function, and we’re attaching an attribute to some class based on data from the request. Likely you’ve already spotted the problem: classes are global singletons, so we’re putting per-request state onto a long-lived object, and in a long-lived web server process, that has the potential to pollute every future request in that process.
The same thing can easily happen in tests, if people try to monkeypatch without a contextmanager like mock.patch. The effect here is pollution of all future tests run in that process, rather than pollution of all future requests. This is a huge cause of flakiness in our test suite. It's so bad, and so hard to thoroughly prevent, that we have basically given up and are moving to one-test-per-process isolation instead.
So that's a third pain point for us. Mutable global state is not merely available in Python, it's underfoot everywhere you look: every module, every class, every list or dictionary or set attached to a module or class, every singleton object created at module level. It requires discipline and some Python expertise to avoid accidentally polluting global state at runtime of your program.
Enter strict modules
One reasonable take might be that we’re stretching Python beyond what it was intended for. It works great for smaller teams on smaller codebases that can maintain good discipline around how to use it, and we should switch to a less dynamic language.
But we’re past the point of codebase size where a rewrite is even feasible. And more importantly, despite these pain points, there’s a lot more that we like about Python, and overall our developers enjoy working in Python. So it’s up to us to figure out how we can make Python work at this scale, and continue to work as we grow.
We have an idea: strict modules.
Strict modules are a new Python module type marked with __strict__ = True at the top of the module, and implemented by leveraging many of the low-level extensibility mechanisms already provided by Python. A custom module loader parses the code using the ast module, performs abstract interpretation on the loaded code to analyze it, applies various transformations to the AST, and then compiles the modified AST back into Python byte code using the built-in compile function.
Side-effect-free on import
Strict modules place some limitations on what can happen at module top-level. All module-level code, including decorators and functions/initializers called at module level, must be pure (side-effect free, no I/O). This is verified statically at compile time via the abstract interpreter.
This means that strict modules are side-effect-free on import: bad interactions of import-time side effects are no longer possible! Because we verify this with abstract interpretation that is able to understand a large subset of Python, we avoid over-restricting Python’s expressiveness: many types of dynamic code without side effects are still fine at module level, including many kinds of decorators, defining module-level constants via list or dictionary comprehensions, etc.
Let’s make that a bit more concrete with an example. This is a valid strict module:
"""Module docstring."""
__strict__ = True
from utils import log_to_network
MY_LIST = [1, 2, 3]
MY_DICT = {x: x+1 for x in MY_LIST}
def log_calls(func):
def _wrapped(*args, **kwargs):
log_to_network(f"{func.__name__} called!")
return func(*args, **kwargs)
return _wrapped
@log_calls
def hello_world():
log_to_network("Hello World!")
We can still use Python normally, including dynamic code such as a dictionary comprehension and a decorator used at module level. It’s no problem that we talk to the network within the _wrapped function or within hello_world, because they are not called at module level. But if we moved the log_to_network call out into the outer log_calls function, or we tried to use a side-effecting decorator like the earlier @route example, or added a hello_world() call at module level, this would no longer compile as a strict module.
How do we know that the log_to_network or route functions are not safe to call at module level? We assume that anything imported from a non-strict module is unsafe, except for certain standard library functions that are known safe. If the utils module is strict, then we’d rely on the analysis of that module to tell us in turn whether log_to_network is safe.
In addition to improving reliability, side-effect-free imports also remove a major barrier to safe incremental reload, as well as unlocking other avenues to explore speeding up imports. If module-level code is side-effect-free, we can safely execute individual statements in a module lazily on-demand when module attributes are accessed, instead of eagerly all at once. And given that the shape of all classes in a strict module are fully understood at compile time, in the future we could even try persisting module metadata (classes, functions, constants) resulting from module execution in order to provide a fast-path import for unchanged modules that doesn’t require re-executing the module-level byte-code from scratch.
Immutability and slots
Strict modules and classes defined in them are immutable after creation. The modules are made immutable by internally transforming the module body into a function with all of the global variables accessed as closure variables. These changes greatly reduce the surface area for accidental mutation of global state, though mutable global state is still available if you opt-in via module-level mutable containers.
Classes defined in strict modules must also have all members defined in __init__ and are automatically given __slots__ by the module loader’s AST transformation, so it’s not possible to tack on additional ad-hoc instance attributes later. So for example, in this class:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
The strict-modules AST transformation will observe the assignments to attributes name and age in __init__ and add an implicit __slots__ = ('name', 'age') to the class, preventing assignment of any other attributes to instances of the class. (If you are using type annotations, we will also pick up class-level attribute type declarations such as name: str and add them to the slots list as well.)
These restrictions don’t just make the code more reliable, they help it run faster as well. Automatically transforming classes to add __slots__ makes them more memory efficient and eliminates per-instance dictionary lookups, speeding up attribute access. Transforming the module body to make it immutable also eliminates dictionary lookups for accessing top-level variables. And we can further optimize these patterns within the Python runtime for further benefits.
What’s next?
Strict modules are still experimental. We have a working prototype and are in the early stages of rolling it out in production. We hope to follow up on this blog post in the future, with a report on our experience and a more detailed review of the implementation. If you’ve run into similar problems and have thoughts on this approach, we’d love to hear them!
Many thanks to Dino Viehland and Shiyu Wang, who implemented strict modules and contributed to this post.
If you want to learn more about this work or are interested joining one of our engineering teams, please visit our careers page, follow us on Facebook or on Twitter.
Python at Scale: Strict Modules was originally published in Instagram Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]>In recent years instagram.com has seen a lot of changes — we’ve launched stories, filters, creation tools, notifications, and direct messaging as well as a myriad of other features and enhancements. However, as the product grew, a side effect was that our web performance began to slow. Over the last year we made a conscious effort to improve this. This ongoing effort has thus far resulted in almost 50% cumulative improvement to our feed page load time. This series of blog posts will outline some of the work we’ve done that led to these improvements. In part 1 we talked about prefetching data and in part 2 we talked about improving performance by pushing data directly to the client rather than waiting for the client to request the data.
Cache first
Since we’re already pushing data to the client at the earliest possible time in the page load — the only faster way to get data to the client would be to not have to fetch or push any data at all. We can do this using a cache-first rendering approach, though this does mean that we have to display stale feed data to users for a short period of time. With this approach, when the page is loaded, we immediately present users with a cached copy of their previous feed and stories tray, and then replace it with fresh data once it’s available.
We use Redux to manage state on instagram.com, so at a high level the way we implemented this was to store a subset of our Redux store on the client in an indexedDB table, and then rehydrate the store when the page first loads. However, because of the asynchronous nature of indexedDB access, server data fetching, and user interactions, we can run into problems where the user interacts with the cached state, but then we want to ensure that those interactions are still applied to the new state when it arrives from the server.
For example, if we were to handle caching in a naive way we could run into the following problem: We begin loading from cache and from the network concurrently and since the cached feed is ready first, we display it to the user. The user then proceeds to like a post, but once the network response for the latest feed comes back it overwrites that post with a copy that doesn’t include the like action that the user applied to the cached copy (see the diagram below).
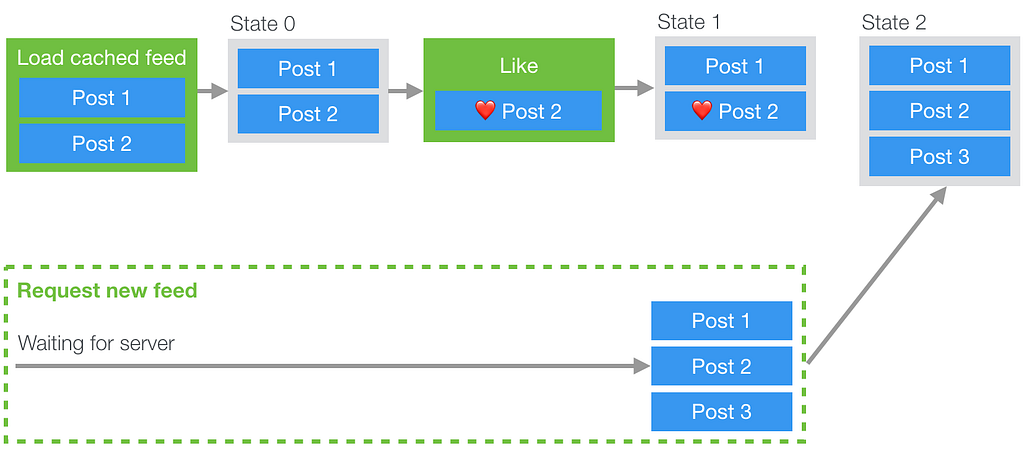
To solve this issue, we needed a way to apply interactions to the cached state, but also store those interactions so they can be replayed later over the new state from the server. If you’ve ever used Git or similar source control systems before, this problem might seem familiar. If we think of the cached feed state as a branch, and the server feed response as master, what we effectively want to do is to do a rebase operation, applying the commits (likes, comments etc.) from our local branch onto the head of master.
This brings us to the following design:
- On page load, we send a request for the new data (or wait for it to be pushed)
- Create a staged subset of the Redux state
- While the request/push is pending, we store any dispatched actions
- Once the request resolves, we apply the action with the new data and any actions that have been pending to the staged state
- When the staged state is committed, we simply replace the current state with the staged one.
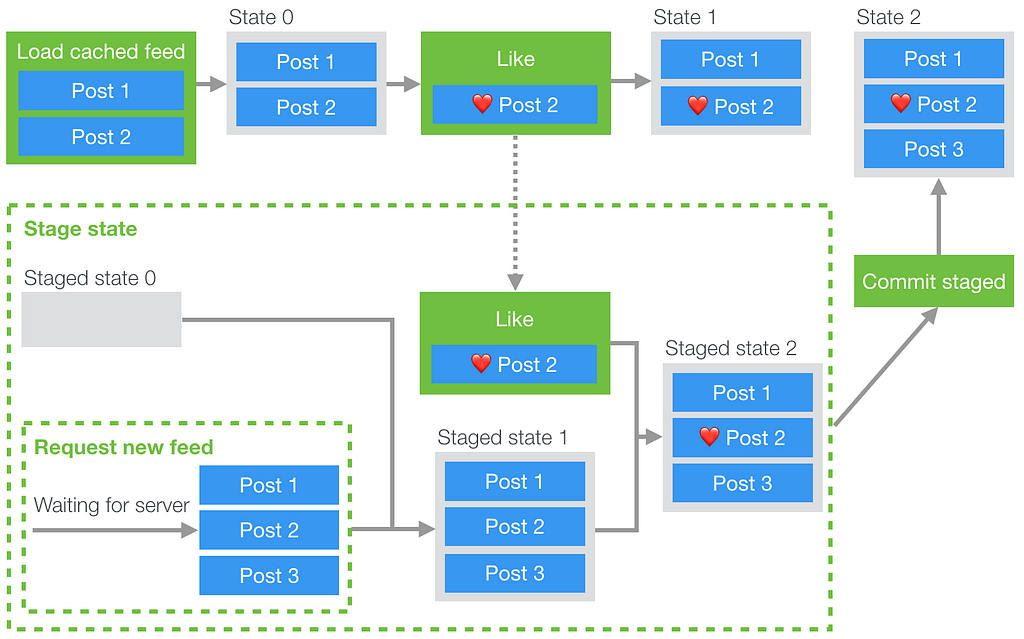
By having a staging state, all the existing reducer behavior can be reused. It also keeps the staged state (which has the most recent data) separate from the current state. Also, since staging is implemented using Redux, we just need to dispatch actions to use it!
API
The staging API consists of two main functions: stagingAction & stagingCommit (as well as a couple of others for handling reverts and edge cases that we won't cover here).
stagingAction accepts a promise that resolves an action to be dispatched to the staged state. It initializes the staging state and keeps track of any actions that have been dispatched since it was initialized. In the source control analogy we can think of this as creating a local branch as any actions that take place will now be queued and applied over the staged state when the new data arrives.
stagingCommit commits the staging state to the current state. If any async actions on the staging state are pending, it will wait before committing. This is similar to a rebase in source control terms, in that we apply all our local changes (from the cache branch) on top of master (the new data from the server), leaving our local branch up to date.
To enable staging, we wrap the root reducer with a reducer enhancer that handles the stagingCommit action and applies the staged actions to the new state. To use all this, we just need to dispatch the relevant actions and everything is handled for us. For example, if we want to fetch a new feed and apply it to a staged state, we can do something similar to the following:
Using cache-first rendering for both feed posts and the stories tray led to a 2.5% and 11% improvement in respective display done times and bought the user experience more in-line with what is available on the native iOS and android Instagram apps.
Stay tuned for part 4
In part 4 we’ll cover how we reduced the size of our codebase and improved its performance through code size and execution optimizations. If you want to learn more about this work or are interested joining one of our engineering teams, please visit our careers page, follow us on Facebook or on Twitter.
Making instagram.com faster: Part 3 — cache first was originally published in Instagram Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]>
One of the most exciting announcements at WWDC this year was the introduction of platform-wide dark mode in iOS 13. During WWDC a group of enthusiastic iOS engineers and designers from Instagram’s design systems team banded together to begin plotting out what it would take to adopt dark mode in our app. This week’s update to Instagram includes full support for iOS dark mode. This took months of work and collaboration between numerous design and engineering teams in the company. As such, we wanted to take some time to share how we approached adopting dark mode and some of the obstacles we encountered along the way.
API Philosophy
Apple did an excellent job shaping how dark mode works in iOS 13. Most of the heavy lifting is done on your behalf by UIKit. Because of this, one of the key principles we had when building out dark mode support in our app was that we should “stand on the shoulders of giants” and try to stick with Apple’s APIs as much as possible. This is beneficial for several reasons.
- Ease of use — UIKit does most of the work in selecting appropriate colors and transitioning between light mode and dark mode. If we wrote our own APIs we’d have to handle this ourselves.
- Maintainability — Apple maintains the APIs so we don’t have to. Any wrappers we have can ultimately be switched over to just use UIKit APIs as soon as our minimum supported OS version is iOS 13.
- Familiarity — Newcomers to Instagram’s iOS codebase who are familiar with how UIKit does dark mode will feel right at home.
That being said, we didn’t use UIKit’s APIs alone since most developers in the company and our build systems are all still using Xcode 10, and introducing iOS 13 APIs would cause build breakages. We went with the approach of writing thin wrappers around UIKit APIs that are compatible with Xcode 10 and iOS 12.
Another principle we followed was to introduce as few APIs as possible, and only when needed. The key reason for this was to reduce complexity for product teams adopting dark mode: it’s harder to misunderstand or misuse APIs if there are fewer of them. We started off with just wrappers around dynamic colors and a semantic color palette that our design systems team created, then introduced additional APIs over time as the need grew within the company. To increase awareness and ensure steady adoption, whenever we introduced a new API we announced it in an internal dark mode working group and documented it in an internal wiki page for the project.
Primitives and Concepts
Apple defines some handy dark mode primitives and concepts, and since we decided to build on top of their APIs we embraced these as well. Covering them at a high level, we have.
- Dynamic colors — Colors that change in response to light mode/dark mode changes. Also can change in response to “elevation” and accessibility settings.
- Dynamic images — Similar to dynamic colors, these are images that change in response to light mode/dark mode changes.
- Semantic colors — Named dynamic colors that serve a specific purpose. For example “destructive button color” or “link text color”.
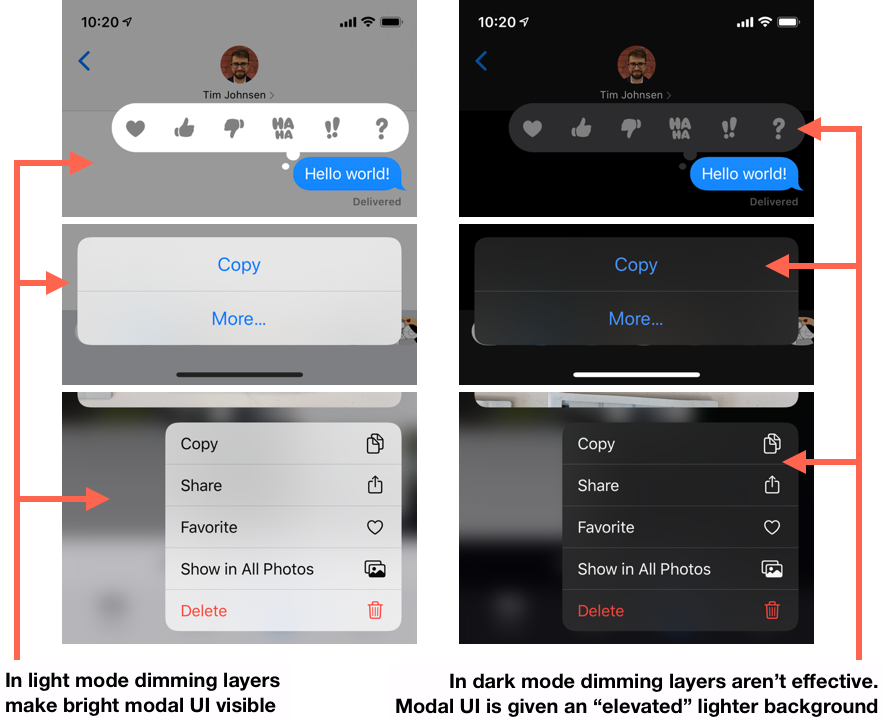
- Elevation level — Things presented modally in dark mode change colors very slightly to demonstrate that they’re a layer on top of the underlying UI. This concept largely hasn’t existed in light mode because dark dimming layers are sufficient to differentiate modal layers presented on top of others.
Building UIKit Wrappers
One of the key APIs iOS 13 introduces for dark mode support is UIColor’s +colorWithDynamicProvider: method, which generates colors that automatically adapt to dark mode. This was the very first API we sought to wrap for use within Instagram and is still one of our most used dark mode APIs. We’ll walk through implementing it as a case study in building a backwards-compatible wrapper.
The first step in building such an API is defining a macro that allows us to conditionally compile out code for people that are still using stable versions of Xcode. This is what ours looks like:
Next we declare a wrapper function. Our wrapper for dynamic colors looks like this:
Within this function we use our macro to ensure that developers using older versions of Xcode can still compile. We also introduce a runtime check so that the app continues to function normally on older versions of iOS. If both checks pass we simply call into the iOS 13 +colorWithDynamicProvider: API, otherwise we fall back to the light mode variant.
You may notice that we’re passing an IGTraitCollection into IGColorWithDynamicProvider's block instead of a UITraitCollection. We introduced IGTraitCollection as a struct that contain's UITraitCollection's userInterfaceStyle and userInterfaceLevel values as isLight and isElevated respectively since those properties are only available when linked with newer iOS versions. More on that later.
Now that we have IGColorWithDynamicProvider we can use it everywhere in the app where we need to use dynamic colors. Developers can use this freely without worrying about build failures or run time crashes regardless of what version of Xcode they or their peers are using. Instagram has historically had a semantic color palette that was introduced in our 2016 redesign, and we collaborated with our design systems team to update all the colors in it to support dark mode using IGColorWithDynamicProvider. Here’s an example of one of these colors.
Once we had this pattern defined for wrapping UIKit’s API we continued to add more as they were needed. The set we ended up with is:
- IGColorWithDynamicProvider as shown here
- IGImageWithDynamicProvider for creating “dynamic images“ that automatically adapt to dark mode.
- IGActivityIndicator functions for creating activity indicators with styles that work in light mode, dark mode, and older versions of iOS.
- IGSetOverrideUserInterfaceStyle for forcing views or view controllers into particular interface styles.
- IGSetOverrideElevationLevel for forcing view controllers into particular elevation levels.
Small side note: We discovered towards the end of our dark mode adoption that our implementation of dynamic colors had equality implications because a new instance of UIColor was returned each time and the only thing that was comparable about each was the block passed in. In order to resolve this we modified our API slightly to create single instances of each of semantic colors so that they were comparable. Doing something like dispatch_once-ing your semantic colors or using asset catalog-based colors and +colorNamed: will produce comparable colors if your app is sensitive to color equality.
Fake Dark Mode
One tricky thing when adopting technologies in iOS betas is getting adequate test coverage. Convincing people using the internal build of Instagram to install iOS 13 on their devices isn’t a great idea because it’s unstable and challenging to help set up, and even if we were to get people testing on iOS 13 the builds we distribute internally were still largely being linked against the iOS 12 SDK so the changes wouldn’t show up anyway.
I briefly touched on our IGTraitCollection wrapper for UITraitCollection that came in handy in the course of building out dark mode. One clever testing trick this IGTraitCollection wrapper afforded us is something we’ve come to call “fake dark mode” — which is an internal setting that overrides IGTraitCollection to become dark even in iOS 12! Nate Stedman, one of our iOS engineers in New York, came up with this setting when we were first working on dark mode.
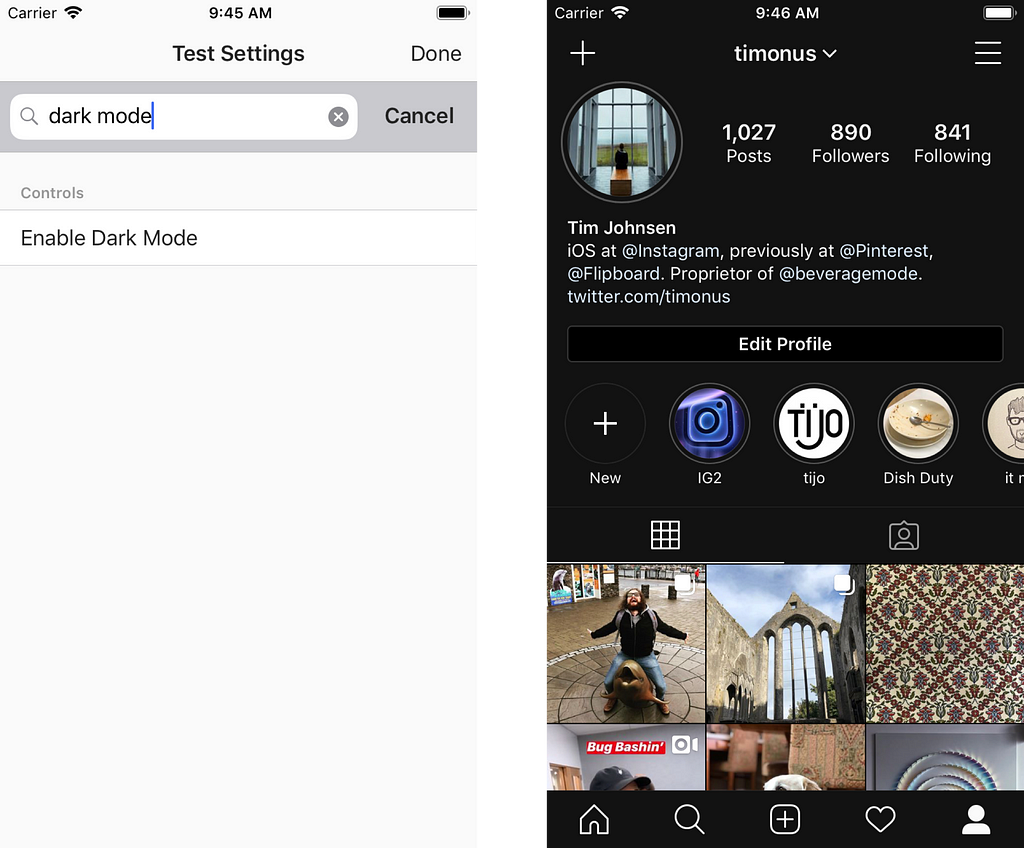
Our API for generating IGTraitCollections from UITraitCollections came to look like this.
Where _IGIsDarkModeDebugEnabled is backed by an NSUserDefaults flag for fake dark mode. There are of course some limitations with faking out dark mode in iOS 12, most notably
- userInterfaceLevel isn’t available in iOS 12, so “elevated“ dynamic colors never appear in fake dark mode.
- Forcing particular styles via our -setOverrideInterfaceStyle: wrapper has no effect in fake dark mode.
- UIKit components that use their default colors don’t adapt to fake dark mode in iOS 12 since they have no knowledge of dark mode.
With this addition to our dark mode wrappers we were able to get much broader test coverage than we otherwise would have.
Conclusion
Dark mode has been a highly requested featured of ours for quite a while.
We had been a little reluctant in introducing dark mode in the past because it would’ve been a tremendous undertaking, but the excellent tools that Apple provides and their emphasis on dark mode in iOS 13 finally made it possible for us! Of course the actual implementation still wasn’t easy, we’ve been working on this since WWDC and it demanded ample design and engineering deep dives into every part of the app (and admittedly, we have probably missed some). This journey has been worth it, on top of the benefits dark mode provides such as eye strain reduction and battery savings, it makes our app look right at home on iOS 13!
A huge thank you to Jeremy Lawrence, Nate Stedman, Cameron Roth, Ryan Olson, Garrett Olinger, Paula Guzman, Héctor Ramos, Aaron Pang, and numerous others who contributed to our efforts to adopt dark mode. Dark mode is also available in Instagram for Android.
If you want to learn more about this work or are interested joining one of our engineering teams, please visit our careers page, follow us on Facebook or on Twitter.
Implementing Dark Mode in iOS 13 was originally published in Instagram Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]>
This interview was conducted by Serena, an Instagram engineering manager.
How did you become an engineer?
When I was in college, the field of Data Science did not yet exist. I studied Statistics & Biometry in undergrad. Later on, I went to graduate school for Engineering.
What was your first coding language?
I used Java when I took my first computer science class, but most of my math and statistics classes required SAS, SPSS, and MATLAB.
What do you listen to while you work?
Believe it or not, I don’t listen to music at all while working. I think it’s distracting. Plus, these days I’m not at my desk long enough to listen to music anyway.
What do you do when you get stuck on a problem?
I like to talk it out with people. Discussing the problem out loud helps me think about the problem differently, and it helps to hear from other people who either have encountered a similar problem before or may look at things from a different perspective.
What do you do when you feel a lot of pressure?
I usually like to take a break. If I have time, I’ll take a walk around the NY building’s floors or our office’s amazing rooftop garden. If I don’t have time, I just take a beat — I take some deep breaths to clear my head, and that can be very helpful.
Please tell us about your favorite project at IG.
This is like being asked to pick your favorite child! My recent favorite is the private like counts test, a product exploration aimed at shifting the focus from the quantity of interactions to the quality of interactions on your feed posts. What I really love about it is that we are challenging the status quo. We are thinking differently about a part of the product that has been a vital part of the Instagram experience from the beginning.
What makes working at Instagram unique?
After two years here, I can confidently say that it’s our culture. One of our values is “people first” — meaning we’re always laser focused on how to create the best experience for our community. We approach every project through the lens of the people who use Instagram.
How would you describe the engineering culture at Instagram?
Very collaborative. We put the Instagram community first, and we work together to create the best products. Everyone here is so passionate about building amazing products for our community, and it’s so energizing to be a part of it.
What makes you excited about coming into work every day?
Working on a product that impacts the lives of billions of people throughout the world. It’s incredibly exciting. It’s also amazing to think about the potential impact we can have with every new idea and project we work on. It’s a huge responsibility, and one that we and I take very seriously.
Your favorite place to eat in the city?
I love sushi. Sushi of Gari is my favorite neighborhood sushi place in New York.
What is your favorite thing to eat at the office?
A smoothie from Frozen Palm, our smoothie bar in the New York office, which provides a lot of great (and healthy!) options.
What’s your favorite Instagram account?
@girlswhocode, which is an organization that I volunteer for. They work on (and post about) important research that’s relevant to women in tech, and their ultimate goal is to help young women find career paths in STEM. I like to follow along to see what programs they’re working on and to hear stories about some of the alumni.

Tell us about your happiest day at Instagram
It was my second Faceversary (second-year mark at Facebook) and my team pulled out all the stops with flowers, cupcakes, etc. My manager, Adam Mosseri, was out of the office, but Nam, our head of engineering, surprised me at a meeting by printing Adam’s face on a piece of paper. We took a selfie with the cutout of Adam’s face, pretending he was there and celebrating with us. It was hilarious, but also very special for me because it was a great way to reflect back on all that’s happened over the past couple of years here.
What is one of the best things you learned while working at Instagram
The importance of good communication and context sharing. We work in such a fast-paced environment that often we assume people have the context they need to do their jobs well. Sometimes, it’s important to slow down and take the time to communicate the bigger picture.
Coolest celebrity sighting at the office?
The cast of Crazy Rich Asians visited the office, and many people were excited to see them in real life. We welcomed Henry Golding, Michelle Yeoh, Awkwafina, Ken Jeong, and book author Kevin Kwan for a FB Live from our New York office where they answered fan questions, and @evachen went Live with the cast from her Instagram account for a Q&A ahead of the film’s release. If you haven’t seen the movie, you’re missing out :)

What does your desk setup look like?
It’s super clean. I am a neat freak and a minimalist too. I think a clean space helps me keep my focus. But it’s hard to keep a clean desk here because there’s always some new piece of swag that manages to make its way onto my desk.
What career advice would you like to give to female engineers who are early in their careers?
So many — but one I’d like to touch on here is the importance of networking. It’s easy to think that we need to just sit at our desks and do really good work, but that’s only one part of the equation.
It’s important to build relationships with people who are not in your immediate team, or company. Networks can open up opportunities for you in the future, and it’s also important to communicate your work with a broader audience. As women, I don’t think we advocate enough for ourselves, and we need to do a better job communicating our accomplishments.
Another is confidence. Women, especially those early in their careers, are often prone to self-doubt. It ends up being our biggest enemy as we second-guess ourselves too much. It prevents us from pursuing opportunities to be challenged and grow. How can we overcome it? For me, what really worked was the “fake it until you make it” mindset. Observe the behavior of your confident colleagues and try to mirror it. On this topic, I really recommend The Confidence Gap.
How do you achieve work-life balance? Do you believe in work-life balance at all? :)
I do! It’s all about setting boundaries and not apologizing for these boundaries. We need to be very diligent about where we draw that line. For me, this might mean that I leave the office by a certain time so I can have quality time with my kids in the evening, and for others it might be something else. The key is sticking to these boundaries and carving out the time that you need to achieve that balance.
Do you think work-life balance is harder to achieve as you become more and more senior in the company?
I don’t think so. The demand definitely becomes greater, but you become better at ruthless prioritization.
Most of the time, I don’t feel hindered by being a female engineer as I don’t have a problem speaking up or leaning in. But there are still times — for example, when I am pregnant — I worry that people will think less of me, and I worry whether I will still be able to meet my colleagues’ expectations. How can we overcome these thoughts?
It’s a really great question and one that goes back to the confidence piece I mentioned earlier. Creating a human being is something to be very, very proud of — it’s amazing!
We need to think about success in our lives in a broader way than just our work. You are building a family, you are a talented engineer, and all of these things are what make you you.
I find that concerns around performance during a pregnancy are often a manifestation of our own self-doubt. While you might not feel as good or sharp as you’re used to, others are probably unaware, and you are your own worst critic. Everyone has good days and bad days, when they’re feeling distracted or not performing their best. We need to be kind to ourselves and be confident in our abilities.
If you want to learn more about this work or are interested joining one of our engineering teams, please visit our careers page, follow us on Facebook or on Twitter.
Interview with Tamar Shapiro, Instagram’s Head of Analytics was originally published in Instagram Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]>