Lessons Learned at Instagram Stories and Feed Machine Learning
Instagram machine learning has grown a lot since we announced Feed ranking back in 2016. Our recommender system serves over 1 billion users on a regular basis. We also now use machine learning for more than just ranking Feed and Stories: we source and recommend posts from Hashtags you follow, blend in different types of content together, and power intelligent app prefetching.
All of the different ways Instagram uses machine learning deserves its own post, but we want to discuss a few lessons we’ve learned along the way of building our ML pipeline.
Modeling Choices
We made a few decisions for how we do modeling that have been beneficial to us either by improving our models’ predictive power and providing top line improvements or by maintaining the accuracy and lowering our memory consumption.
First off we went with caffe2 as our general modeling framework, meaning we write and design our models through that platform. Caffe2 is significantly more optimized for our workflows than other options, and it gives us the most headroom with model weight per CPU cycle at inference time. “Stack Footprint” is an important metric for the ML team because we use several CPU intensive statistical techniques in our networks (pooling, etc).
We also use models with ranking losses and point-wise models (log loss for example). This gives us more control in our final value function so we can fine-tune trade offs between our key engagement metrics.
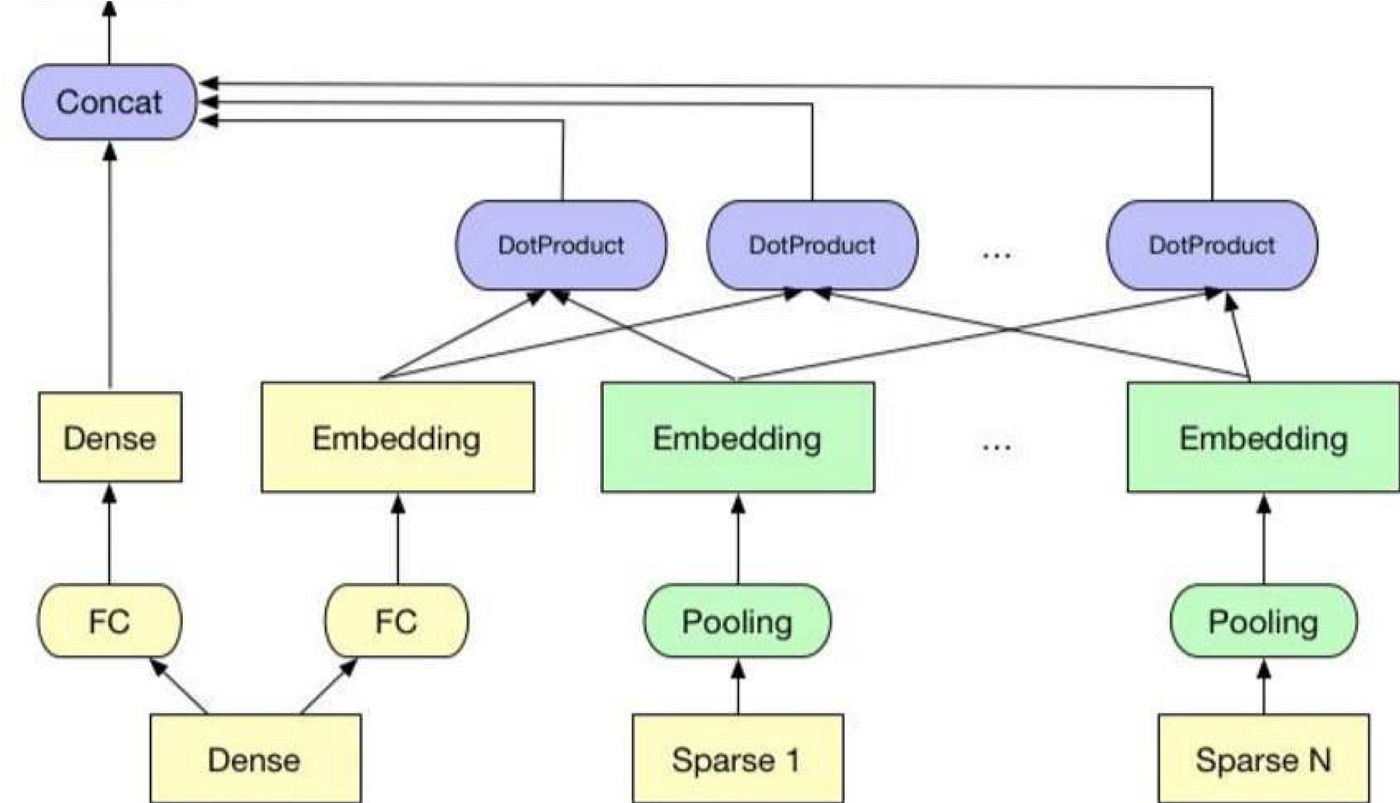
In terms of core machine learning, we saw some very good accuracy wins by taking into account position bias in our model. We added a sparse position feature to our last fully connected layer to avoid confusing the model too much. In general, co-learning sparse embeddings is another impactful area for us, that comes in many flavors to properly capture our users’ interests.
We tune our final value function regularly by fitting a Gaussian Process to learn the effect of the value functions’ parameters on our top line metrics measured through series of A/B tests.
Data Freshness and Trends
Our users’ habits change over time. Similarly, the ecosystem is subject to trend effects (during seasonal events such as the Superbowl). Because of this, data freshness is important. Stale models cannot capture changes in user behavior or understand new trends.
Quantifying the effects of data freshness was helpful to us. We monitor the drift in KL-divergences between key behavioral distributions to inform us of the “staleness” of our pipeline.
One way to keep our models fresh is to have online learning models or at least some periodic training. In this setting, one of our biggest challenges was coming up with a reasonable adaptive learning rate strategy since we want new examples to still matter in gradient updates (even for models that have been training on months of data).
Novelty Effects
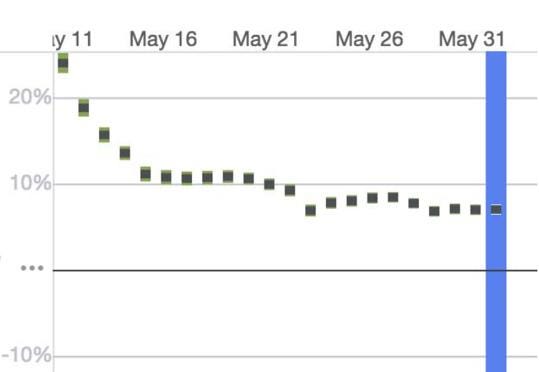
Novelty effect are another hard problem that we face. We frequently run A/B tests where the treatment arm shows positive engagement for the early days and slowly trends down to neutral.
On one hand it’s actually quite telling that subtle changes can temporarily drive engagement. We believe it stems from the fact that long running models tend to “exploit” too much and those tests bring some new areas of exploration.
The time scale of these effects are also interesting. We’ve seen changes that would take over a month to plateau (with engagement trending up or down).
On the other hand, we learned the hard way that novelty effects can be subtle and should be carefully controlled while launching new experiences that may be effected. We recently had a rather serious post-mortem where two experiments prone to novelty effects interacted together very poorly in the few hours after launch.
While it isn’t perfect, we now have some modeling that can predict the magnitude and the length of novelty-prone experiments. With this we can iterate faster by mitigating risk and terminating tests earlier.
Experimentation (A/B) Small Effects
There are many different complexities with large scale ML and A/B testing. Besides the novelty effects mentioned above, we also face statistical problems. Imagine having 10 ranking engineers each launching a new test everyday: it’s quite likely that several of those tests improve engagement metrics with statistical significance!
On top of that, some of those experiments may only target specific cohorts of users, and the measured effects aren’t necessarily as important on the overall population. This makes the test results even harder to assess.
Our current set of best practices try to make sensible trade offs between engineer iteration speed and our confidence interval in the changes we launch. These best practices require strict replication on increasingly larger population of users before we approve an A/B test for production.
Learnings-as-Impact and Scientific Method
Machine learning is a stochastic process by definition. When we do performance reviews, our engineers and researchers are calibrated against traditional software engineers working on less volatile projects. It is entirely possible to do all the right things but to come up short in terms of bottom line metrics.
At Instagram, we are keen to stick to the scientific method for our experimentations. Even if an A/B test doesn’t directly result in a launch, we can often leverage it to provide interesting product insights in the future.
This also prevents bad scientific patterns of random-walking through the hyper parameters of our pipelines to find some local optima. We now call this pattern “human gradient descent”. With this, we require principled hypothesis to verify before launching a test.
As machine learning engineers, we aren’t just looking to ship features, but we also want to learn. Each experiment has a specific set of outcomes. We’re not random walking.
Normalization
Blending different types of content is another challenge we faced. For example, a video and a photo have very different distributions for the possible actions. For example you could imagine that “liking” a post and “commenting” on a post or “completing” a video are three actions with very different distributions (likes happen more often than comments, etc.)
Naively it makes more sense to rank photos with P[Like] (probability of a viewer liking a post) and videos with P[completion] (probability of a viewer viewing more than X% of a video). That puts machine learning engineers in a difficult position when we want to merge the lists to come up with a final ordering for the viewer.
We tackled this problem by fitting a mapping from one value function distribution (such as P[Like]) to a reasonably well-behaved distribution such as a Gaussian. In that output space, the lists are now comparable and we can unambiguously say a piece of content is superior to another one.
Iteration Speed — Offline Analysis
We were way too late with adding a proper backtesting framework. For very large scale and impactful machine learning systems, engineers and researchers really need to open up the models and understand as precisely as possible the effect their experiment has. It’s very hard to do this without solid tooling. We worked on a replaying tool that takes in whatever new model/ranking configuration you want to test and outputs a panel of useful metrics to understand the overall ecosystem impact that your change may have.
Our goal with this is to reduce as much online experimentation as possible to reduce the risk of exposing users to bad experiences and to speed up our iteration speed.
Tooling and Infrastructure
All large-scale systems require serious infrastructure, and thankfully at Instagram we have a stellar ML Infrastructure team (they originally built Feed ranking and spun out from it). All model inference, features extraction, training data generation and monitoring is taken care of by their infrastructure.
Not having to worry about scaling concerns and focussing fully on statistical modeling is one of the most significant efficiency boosts for our engineers. On top of that, the ML infra team create tools that let us dive deep to understand our models better which help us improve our users’ experience.
Personalization
Another beneficial feature is the ability to fine-tune our final value function. This takes our models as input, adds our business logic, and returns a final score per media. Personalizing that value function is both impactful and complex. We chose to to have high level heuristics around cohorts of users who benefit less from our recommendation system and tune the value function specifically for them.
Another personalization strategy that shows promising early results is factoring in some user affinity models. Trying to quantify how much affinity a user may have with other users/types of content helps us tailor and fit our function specifically to our viewers.
Value Modeling
Finally we have our value model: the formulaic description that combines different signals into a score and incorporates our business logic. This is complex code where product heuristics meets statistical predictions.
We’ve seen significant improvements over the years by tuning this value model. We typically use Gaussian processes and Bayesian optimizations to span the space of hyper parameters of the model and find a region that works well for us. There is another article detailing this procedure here.
Parting Thoughts
We hope that this summary of our machine learning pipeline and problems we face is helpful. In future posts, we will go in even more depth on some of the issues mentioned above.
Whether we are predicting user actions, building content understanding convolutional neural networks, or creating latent user modes, these lessons help us make fewer mistakes and iterate faster so we can constantly improve ML for everyone on Instagram!
If you are excited to apply machine learning to provide value to our global community at scale, we’re always looking for more great talent to join us.

